출처: AI 엔지니어 기초 다지기 : 네이버 부스트캠프 AI Tech 준비과정
돌다리도 다시 두들겨보고 건너는 개념 복습 게시물
정형데이터: 행(하나의 데이터 인스턴스), 열(데이터 피처)로 표현 可 데이터 -> 범용적임(가장 기본 소양)
이면에 숨겨진 진실을 찾는 통찰력 중요
ex) 전쟁에서 무사히 돌아온 비행기 도면에 표시된 총알 자국을 보고, 격추된 비행기에는 총알 자국이 없는 곳에 공격을 당했다고 파악, 해당 부분을 철판으로 더 보강
비정형데이터: 이미지, 비디오, 음성, 자연어 등 정제되지 않은 데이터 (요즘 트랜드)

[문제 정의]
X = 5914명 고객 2009.12 ~ 2011.11 구매기록
Y = 5914명 고객 2011.12 총 구매액 > 300 여부 (Binary) -> 우량고객 예측(타겟 마케팅, 고객 추천, 혜택 개인화)
[문제 이해]: 어떤 피쳐를 만들어야 ML 성능이 좋아질까
Test data에 대한 모델 성능이 잘 나오려면 많은 가설을 세우고 실험을 하고 검증을 거쳐봐야한다.
Ex) Aggergation을 할까, 구매일자가 있으니 시계열을 할까, 아니면 둘 다 할까 등
+ 무엇을 Train, 무엇을 Valid, 무엇을 Test로 세워야할까? (특히 valid 선정 전략 유의!)
[ML 평가지표 이해]
분류 <-> 회귀(연속형 숫자 예측) 에 따라 달라짐
여기 문제는 분류문제이다.
[분류문제 - Confusion Matrix]

1. Accuracy(정확도) = (TP+TN) / 전체 합 = 전체 데이터에서 제대로 분류한 비율
문제점: 불균형 데이터에는 부적절함
Ex) 100명중 1명만 암환자일 때, 100명 모두 정상으로 예측하면 Accuracy는 99%임. 암환자 예측 못하는게 의미있을까?
2. Precision(정밀도) = TP / (TP+ FP) = True 예측값이 진짜 True인 정도 = Negative 데이터가 더 중요한 경우
Negative를 Positive로 판단하면 안될 때 사용 ex) 스팸메일 자동 분류시, 스팸이 아닌 것을 스팸으로 분류하면 안됨
3. Recall(재현율) = TP / (TP + FN) = 실제 True값을 얼마나 많이 예측했는지 = Positive 데이터가 더 중요한 경우
Positive를 Negative로 판단하면 안될 때 사용 ex) 악성 종양을 음성으로 판단하면 환자 생명이 위급해
4. ROC(Receiver Operating Characteristic Curve = 수신자 조작 특성)
y축 = 1을 1로 예측한 비율(TPR), x축 = 0을 0으로 예측한 비율(FPR) 으로 두고 모델 임계값을 변형하며 그린 곡선
5. AUC(Area Under Curve): ROC곡선의 면적 in [0, 1]: 1은 잘 예측한 것, 0은 잘 예측 못한 것
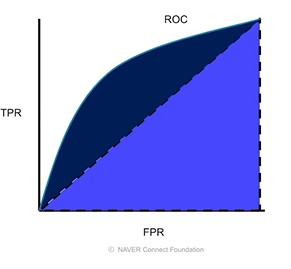
여기서 대각선은 0.5를 나타낸 것.
ML모형은 최소한 0.5보다는 높게 나와야한다.
기본 연습문제
1. numpy로 행렬 곱셈 구현
import numpy as np
## 코드시작 ##
mtx = np.random.rand(5,3) @ np.random.rand(3,2)
## 코드종료 ##
print(mtx, mtx.shape)[[1.42602205 0.91532358]
[1.68858305 1.13888797]
[1.19449442 0.70567315]
[0.23113163 0.16221297]
[1.10814626 0.85595289]] (5, 2)
2. numpy로 concatenate 연산(array 수직, 수평 나열)
## 코드시작 ##
arr1 = np.array([[5,7], [9,11]])
arr2 = np.array([[2,4], [6,8]])
arr_v = np.concatenate((arr1, arr2), axis=0) # 수직연결
arr_h = np.concatenate((arr1, arr2), axis=1) # 수평연결
## 코드종료 ##
print(arr_v, arr_h)[[ 5 7]
[ 9 11]
[ 2 4]
[ 6 8]] [[ 5 7 2 4]
[ 9 11 6 8]]
3. 조건에 따른 Series 코드 완성
import pandas as pd
idx = ["HDD", "SSD", "USB", "CLOUD"]
data = [19, 11, 5, 97]
## 코드시작 ##
table = pd.Series(data, index = idx)
series = table[table.apply(lambda x: 10<= x <=20)]
## 코드종료 ##
print(series)HDD 19
SSD 11
dtype: int64
4. 그외 numpy 연습
import numpy as np
# 주어진 리스트
data = [10, 25, 40, 55, 70]
## 코드시작 ##
# 1. numpy 배열로 변환하여 출력하세요.
dt = np.array(data)
print(dt)
# 2. 리스트의 모든 원소의 합을 계산하여 출력하세요.
print(np.sum(dt))
# 3. 리스트의 모든 원소의 평균을 계산하여 출력하세요.
print(np.mean(dt))
# 4. 리스트의 최댓값과 최솟값을 출력하세요.
print(np.max(data), np.min(data))
# 5. 각 원소를 10으로 나누는 연산을 수행하고 결과를 출력하세요.
print(dt / 10)
# 6. 각 원소를 3으로 거듭제곱하는 연산을 수행하고 결과를 출력하세요.
print(dt ** 3)
## 코드종료 ##[10 25 40 55 70]
200
40.0
70 10
[1. 2.5 4. 5.5 7. ]
[ 1000 15625 64000 166375 343000]
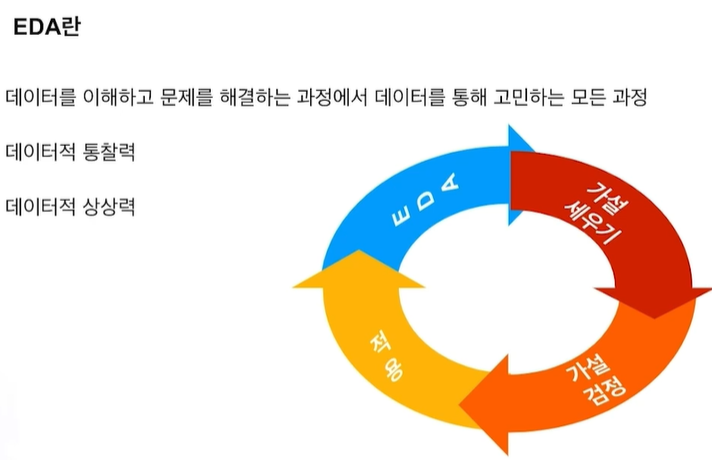
EDA(Exploratory Data Analysis: 탐색적 데이터 분석)
데이터 탐색하고 가설을 세우고 증명하는 과정, 이해하고 특징을 찾아내는 과정
이런 과정이 반복: Data에 대한 가설 혹은 의문 -> 시각화, 통계량 혹은 모델링을 통한 가설 검정 -> 결론을 통해 다시 새로운 가설 혹은 문제 해결
데이터 종류, 사용 모델에 따라 EDA 방향성 다양함. 일반화X 정해진 답X
결론: 최대한 많은 가설, 의문을 생각하고 풀어나가자
방법 1) 개별 변수 분포(Variation) 파악 -> 변수간 분포 관계(Covariation) 파악
예제: 타이타닉
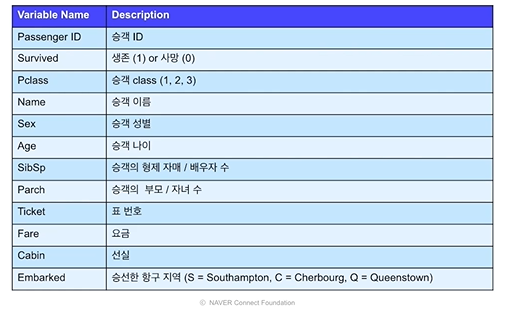
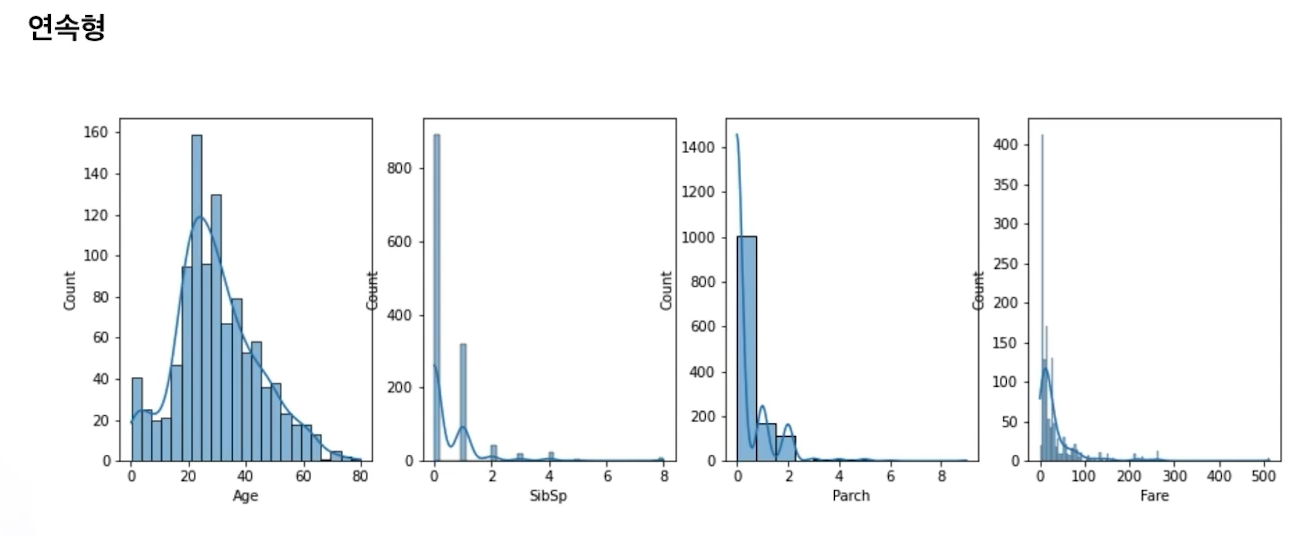
Age를 제외한 나머지는 왼쪽에 치우친 포아송 형태다.
Age는 20에서 40구간이 많다.
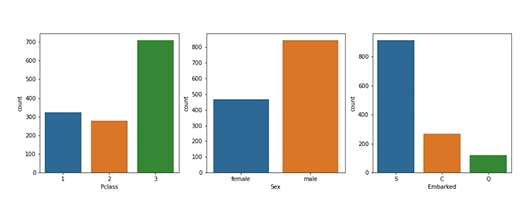
P: 2가 적고 3이 많음. 상식적으로 1이 적은경우가 맞다는걸 생각해본다.
성별: 남성이 더 많다. 왜 그럴까? 생각할 여지 有
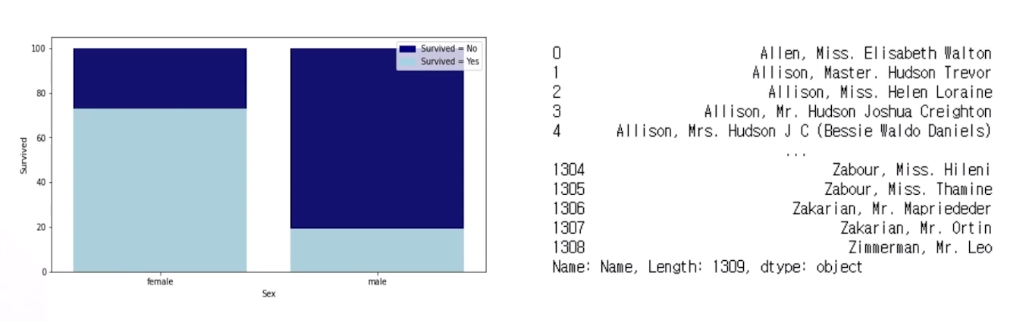
남성이 여성에 비해 사망 ↑ -> 여성을 우선적으로 탈출할 수 있도록 배려한 것 아닐까?
그렇다면 같은 성별 내에서 사망률 차이는 없었을까? (추가 꼬리질문)
Name을 통해 성별, 호칭을 통한 기혼여부 파악을 할 수 있다.
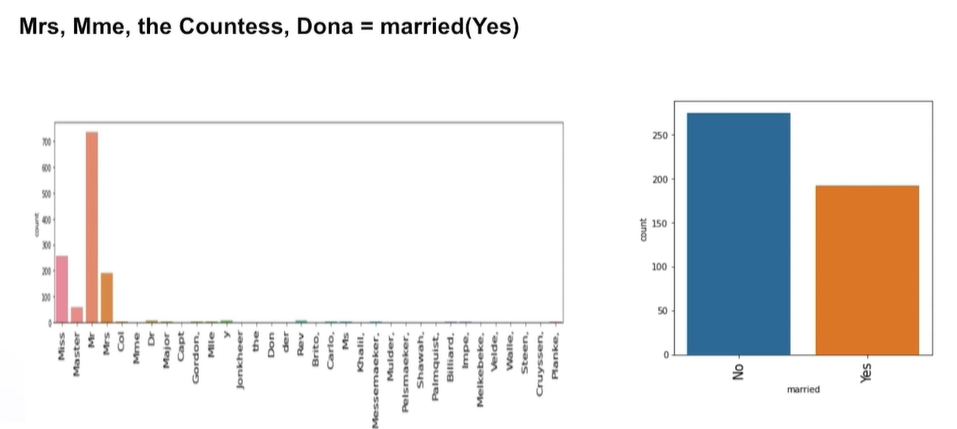
이것을 통해 다시 target(생존률)을 파악
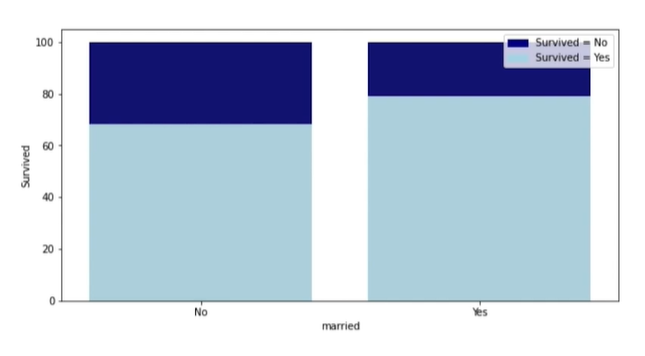
기혼 여성 생존률↑ -> 기혼 여성은 아이가 있으므로 구명보트를 먼저 탈 기회를 얻지 않았을까?
기혼자와 기혼자가 아닌 사람들간의 차이가 왜 났을지에 대해서는 여러가지 상상이 가능하다.
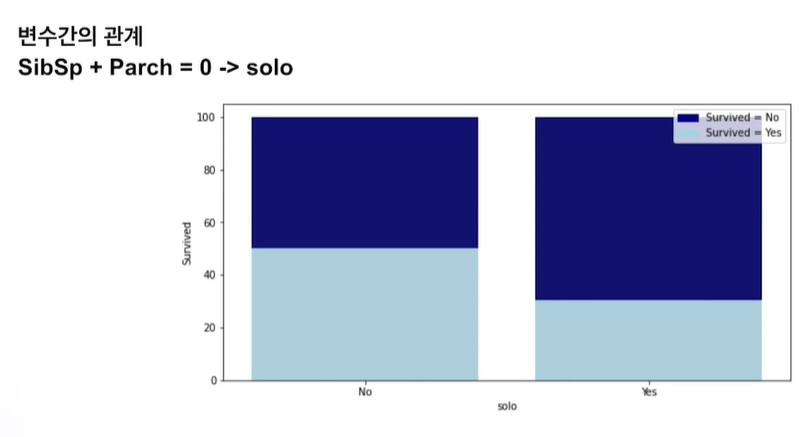
그러면 가족 규모에 따라서 생존률이 차이가 날까? (싱글, 5인 이상을 Large, 그 사이는 Medium이라 한다면?)
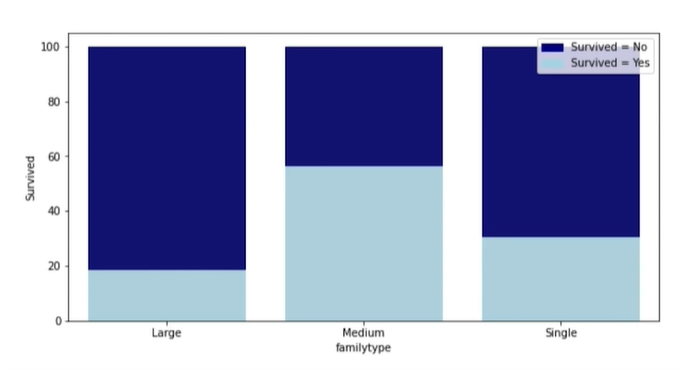
오히려 가족이 너무 많으면 역효과가 나는 듯 하다
방법 2) 문제 이해 및 가설 세우고 검증하기 (다른 방법의 EDA)
예제: 아까 그 제일 처음 소개했던 그 데이터
가설 세우기 예)
이전 달 total이 영향을 주었을까?
작년 12월 달의 total이 영향을 주었을까?
Country(거주 국적)에 따른 영향이 있을까?
고객마다 주로 구매하는 품목이 있다면 Target에 어떤 영향을 줄까?
이러한 가설을 확인하면서 데이터 특성 파악 이해!
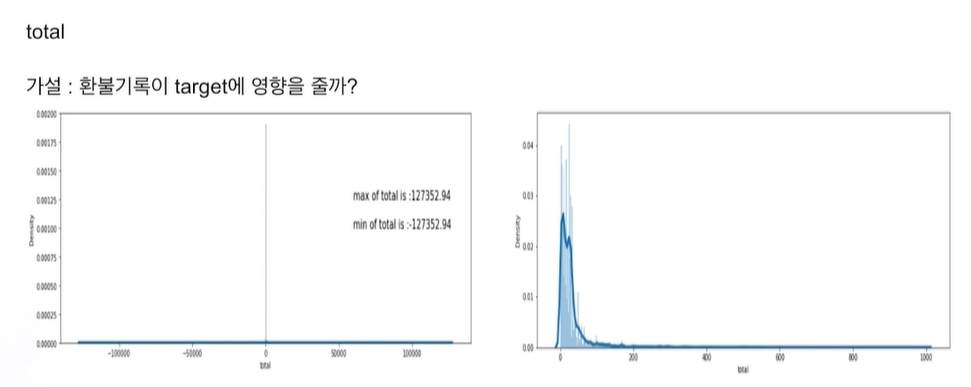
음수 -> 환불한 경우
min과 max 절대값 동일 -> 환불한 경우구나 라고 이해
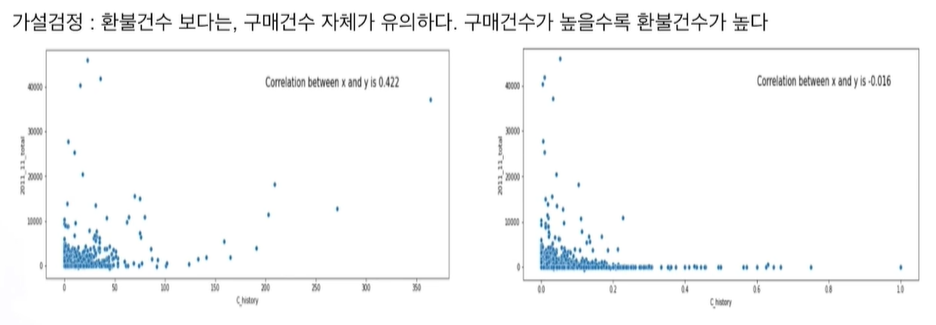
환불 건수와 total의 상관관계가 0에 가깝기 때문이다.
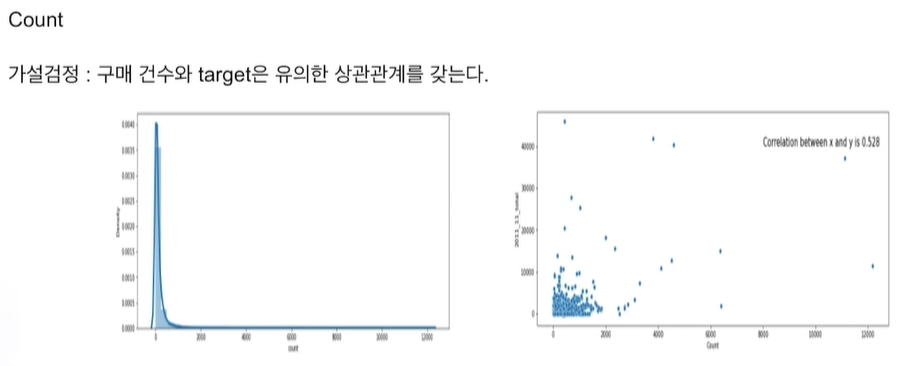
대부분 한 곳에 몰린 분포이지만 종종 특정 고객이 엄청난 구매량을 보임
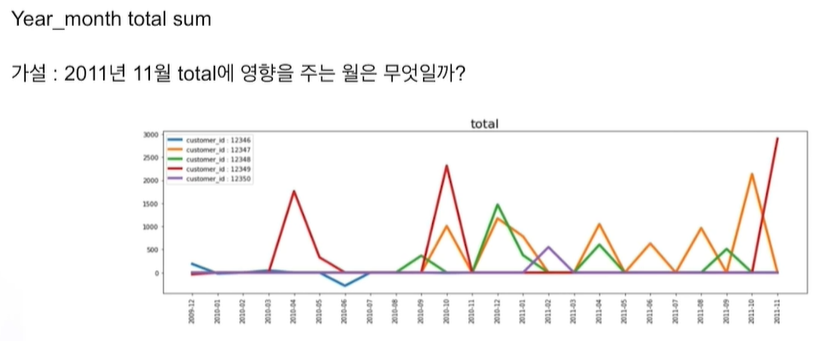
특정 월에 구매 안함 = 0
주문 후 환불 = 음수 데이터
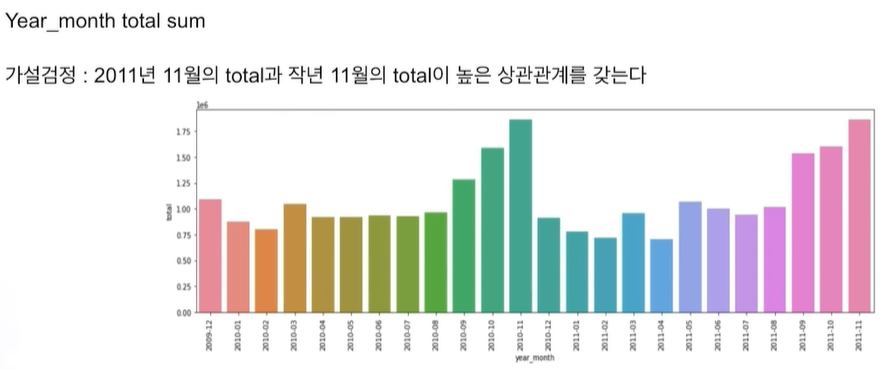
연말에 전반적으로 올라가고 매년 그럼. 12월은 안높음.
고객이 일반고객이 아니라 소매점이면 12월을위해 11월에 미리 대량 구매하는 것일까? 생각 可
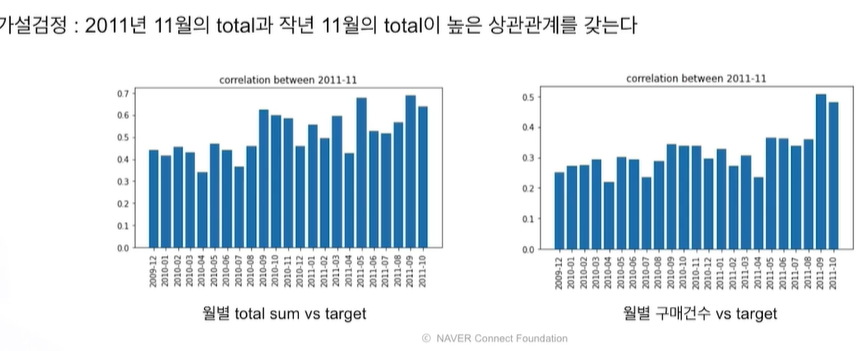
왼쪽: 작년 11월과 관련, 가까운 시기와 상관관계
오른쪽: 작년 11월과 거리 있음. 가까운 시기에만 상관관계
이런 과정을 통해 피쳐를 새로 만들거나 해서 모델 성능을 올릴 수 있는 것이다.
그럼 범주형 데이터에 대해서도 해보자.
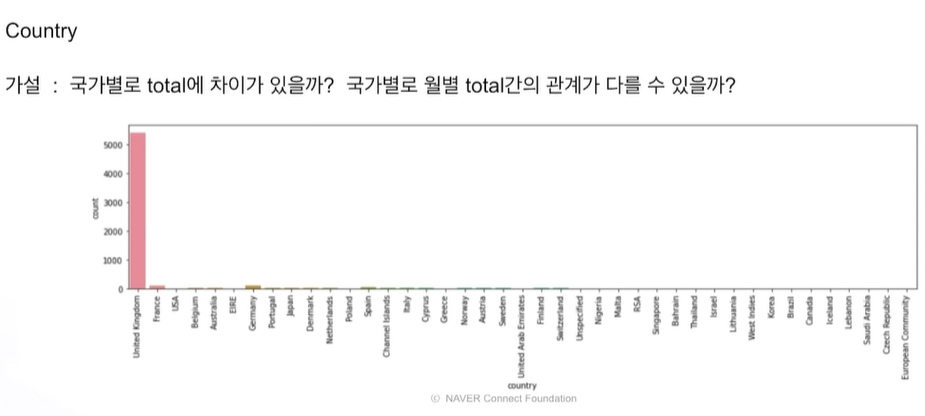
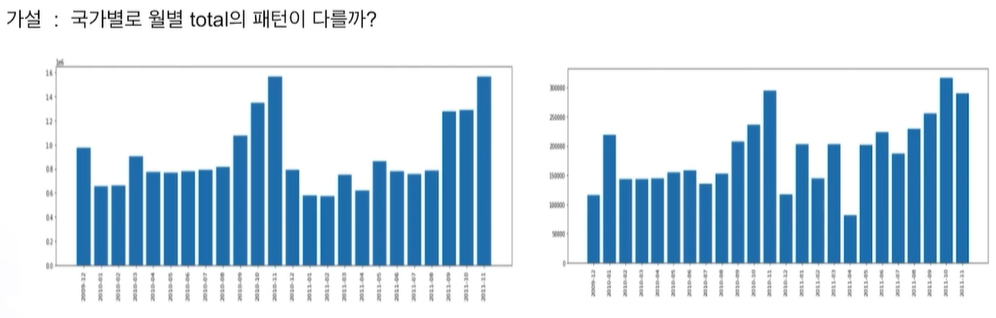
일부 차이는 있지만 큰 차이 없음 -> 굳이 국가 변수 필요 없을
문자열 데이터 처리
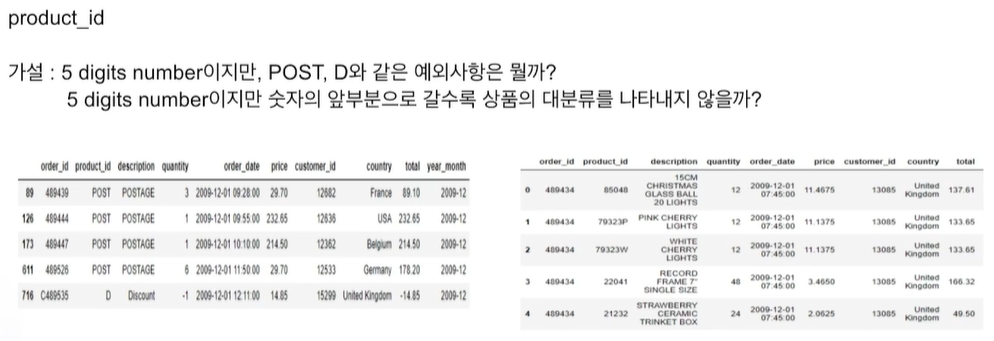
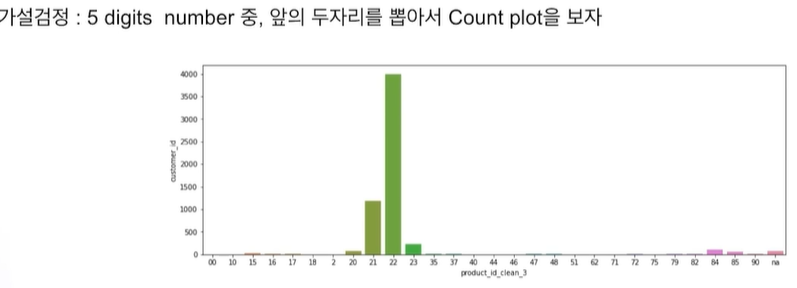
숫자가 너무 적은건 하나로 묶어도 되지 않을까라는 결론이 생김

이번엔 WORD 클라우드를 살펴본다.


다양한 NLP기법을 통해 feature로 바꿀 수 있다.
데이터 전처리(Preprocessing)
ML에 데이터 입력하기위해 처리하는 과정. (EDA에따라, 모델(선형,트리,딥러닝 등), 목적에 따라 달라짐)
예제: Sklearn의 Boston Datasets
연속형 데이터 처리: 선형기반(선형회귀, 딥러닝 등)은 변수 간 스케일 맞추는게 필
1) Scaling
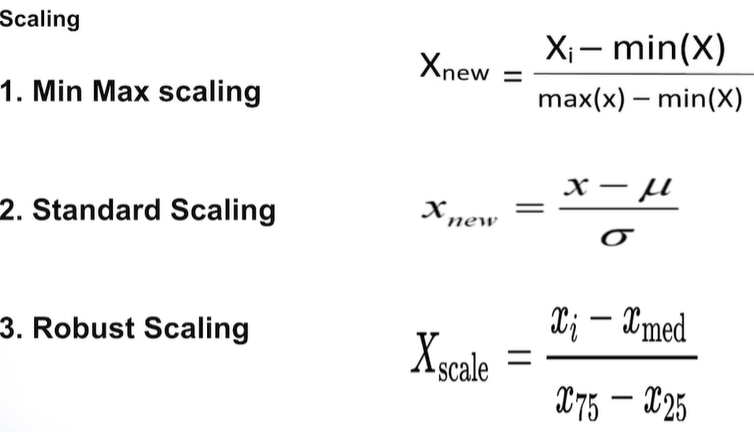
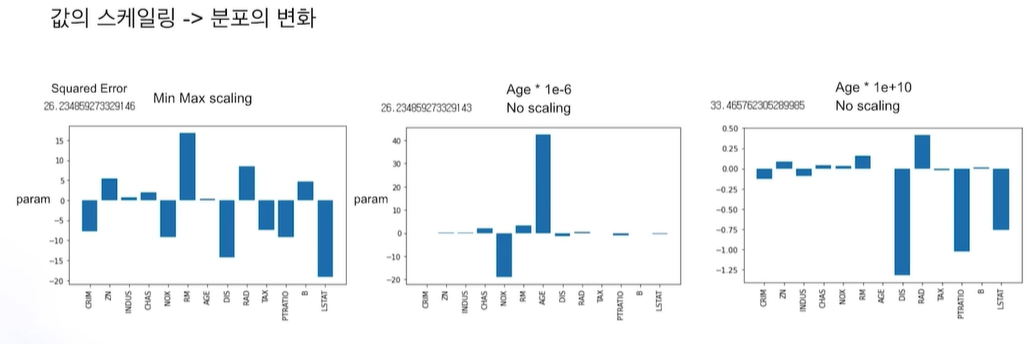
3번이 이상치 영향 덜 받음
2) Scaling + Distribution
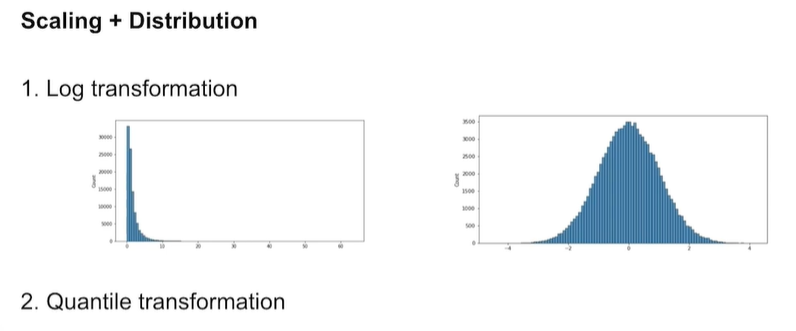
log는 정규화에 가깝게 해줌. exponential transformation은 log와 반대로
Quantile transformation은 어떤 분포가 들어와도 uniform 혹은 정규분포로 만들어줌
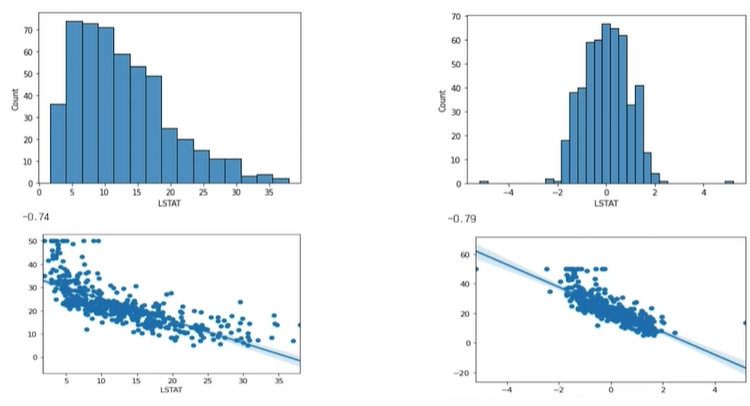
-> 선형모델에서 성능이 올라감
3) binning: 연속형 변수 -> 범주형 변수로 바꾸는 것
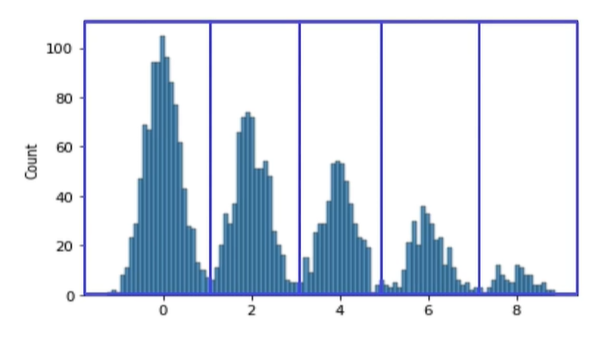
이런식으로 연속형 데이터 다봉분포 데이터일때 사이사이가 유의미하지 않는 구간이 있다.
트리모델을 사용할 경우 이런 데이터가 overfitting 문제를 야기한다.
범주형 데이터 처리: Encoding(인코딩)을 한다.
머신러닝에 수치형 변수로 바꿔주는 인코딩이다. 인코딩 방법은 여러가지이다.
1. One hot encoding: 범주형에 대해 0과 1로 이진분류로 변환
문제점: 카테고리가 너무 많으면 컬럼 너무많이 생김-> 메모리 문제, 차원 저주 -> 모델 성능 저하
2. Label Encoding: 다중분류로 인코딩
문제점: 모델이 이 숫자를 가중치나 순서로 인식할 수 있음 (특히 선형모델)
3. Fequency Encoding: 몇 번 등장하는지 숫자를 문자열 대신 표현
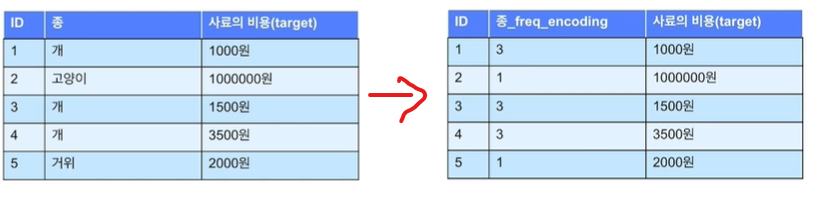
장점: 의미가 있는 정보(빈도수)로 인코딩
문제점: 중복 인코딩이 생길 수 있음 (고양이 = 거위 가 되버림)
4. Target Encoding: target변수의 평균값을 문자열 대신 입력하여 변환
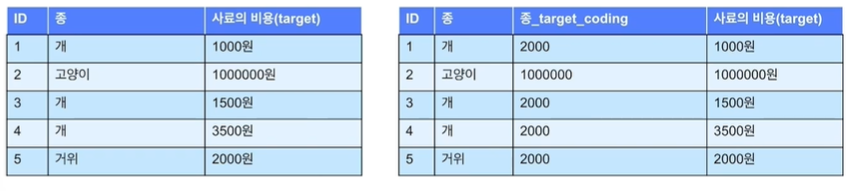
장점: 의미가 있는 정보(타겟 평균)로 인코딩
문제점: 중복 인코딩이 생길 수 있음 (개 = 거위가 되버림), 후에 새로 생기는 종에 대해서 인코딩 불가. 타겟정보와 직접적 연관이므로 모델에 사용하면 overfitting 우려
5. Entity Embedding: Word2Vec를 통해 문자열 데이터 인코딩
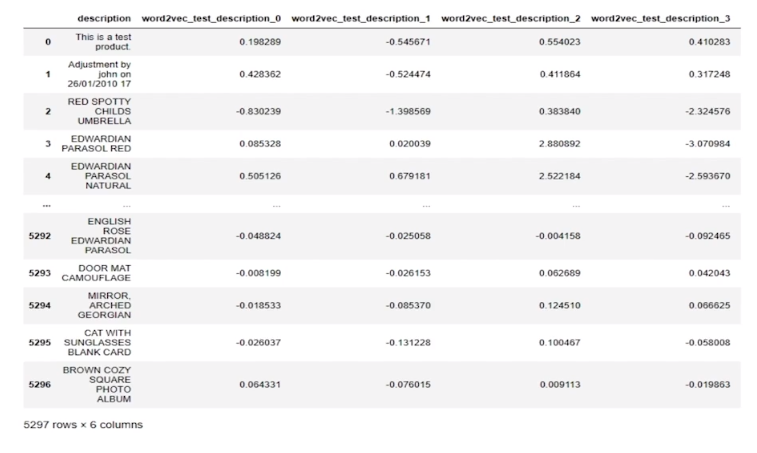
결측치 처리
1. 패턴 파악
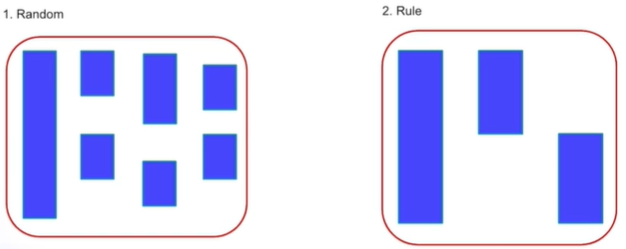
보통은 1번이지만 2번의 경우처럼 규칙적으로 결측치가 나타날 수 있다.
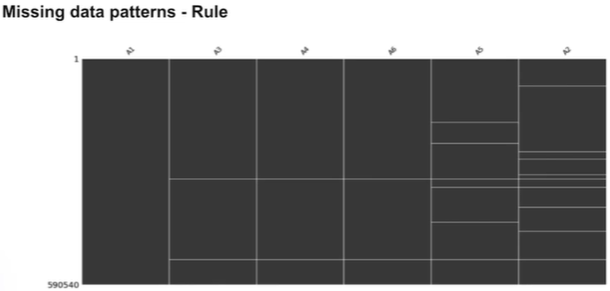
이 경우 규칙이 있으므로 직접 확인하여 어떤 특성이 있는지 파악한다.


Univariate: 보통은 이런식이기 때문에 단(다)변량 기법을 사용해서 채워야 한다.
1) 제거: 데이터 많으면 可. Target data랑 엮인 경우 좋은 방법은 아님. 그런데 전반적으로 해당 피쳐 결측치가 큰 경우 모델 영향력에 적을 것을 예상하고 해당 변수 자체를 제거 可
2) 평균값 삽입:
3) 중위값 삽입:
4) 상수값 삽입:
2~4번 방법은 결측치가 많은 경우 문제 可
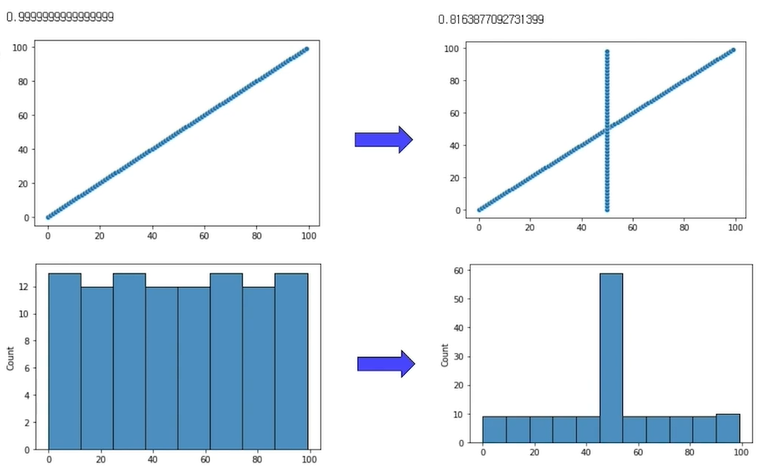
2번 방법으로 했는데 상관관계가 망가졌다.
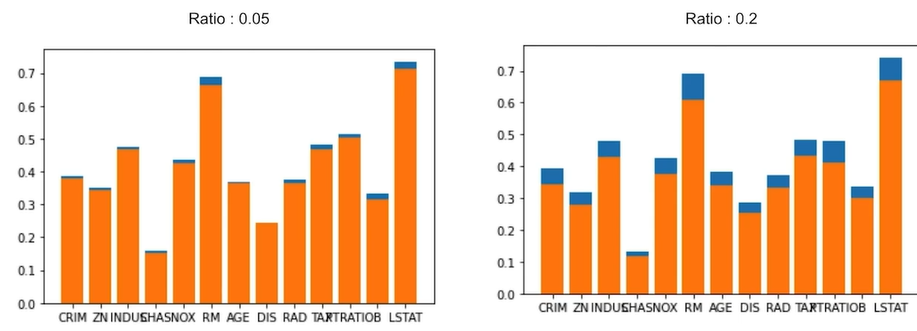
왼쪽처럼 결측치 비율이 5%인 경우 2~4번방법을 써도 큰 차이는 없지만 오른쪽처럼 20%인 경우 Target과의 상관관계가 크게 감소한다.
그럼 결측치 채우려면? : ML통해서 주변변수를 통해 값을 예측하거나, 결측치 sample과 가장 유사한 것을 찾아서 채우는 방법이 있음
1) 회귀분석으로 X2~Xn로 X1예측, X2를 X1 ~ Xn 예측 .. 반복
2) KNN nearest 이용
ML사용시 결측치가 많으면 시간 소요 多 -> 데이터 크기에 따른 적절한 판단 필요
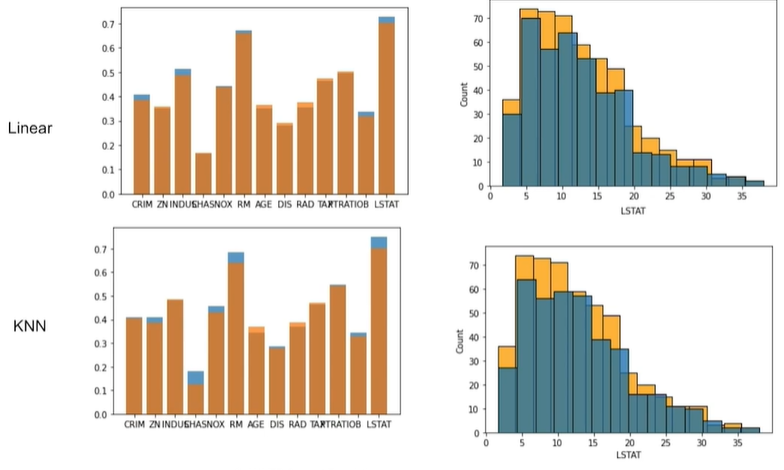
기존 2~4방법보다 회귀나 KNN방법이 상관관계를 상대적으로 잘 보존하고 있다.
꼭 방법론이 아니더라도 합리적 접근법(상식?)으로도 채울 수 있다. 예제는 다음과 같다.

이상치(Outlier) 처리
선형모델: 이상치 처리하는게 적절
트리모델: 이상치에 영향을 덜 받으므로 모델 성능에 따라 결
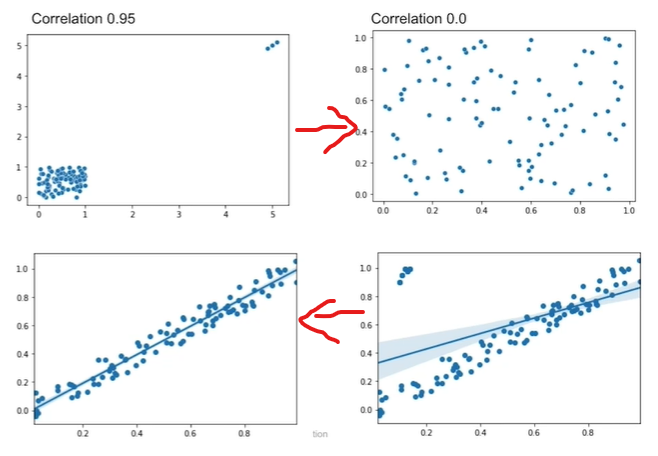
위의 케이스는 이상치를 제거했더니 실은 선형관계가 없는 랜덤 분포라는 것을 알려줌
아래 케이스는 이상치를 제거했더니 선형관계가 더 뚜렷해짐
탐색방법: Z-Score, IQR로 탐색 가능
이상치 발생 이유를 안다면 그 의미를 알고 그에 맞게 처리를 할 수 있다.
또한 train에서 처리를 했다면 당연히 test에도 동일하게 처리해야
1. 원인을 알고 그에 맞게 처리하기
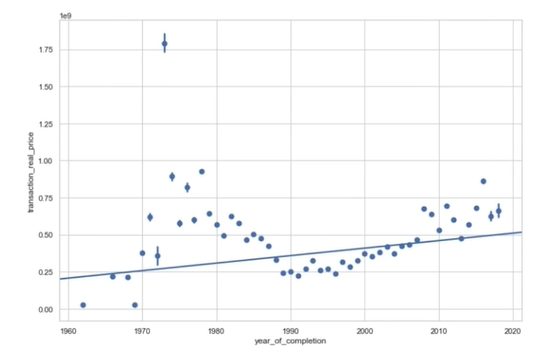
70~80년대에 유달리 높은 아파트 가격(이상치)? -> 재건축(재개발) 이유로 높아짐
-> 재개발(재건축) 요인을 변수로 추가해서 이상치 문제 해결!
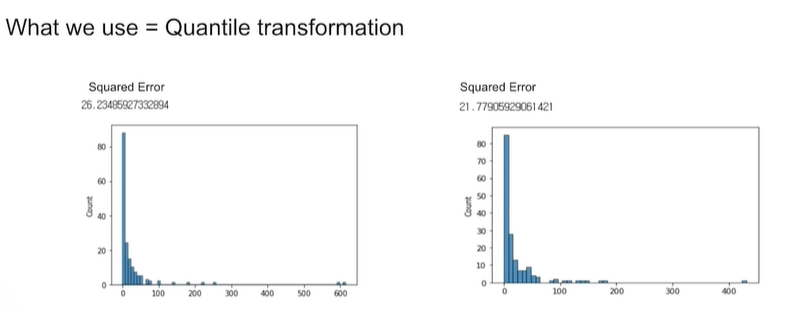
2. 모델 성능 측면에서 처리하기
데이터를 차원축소해서 2차원으로 그린 그래프이다.
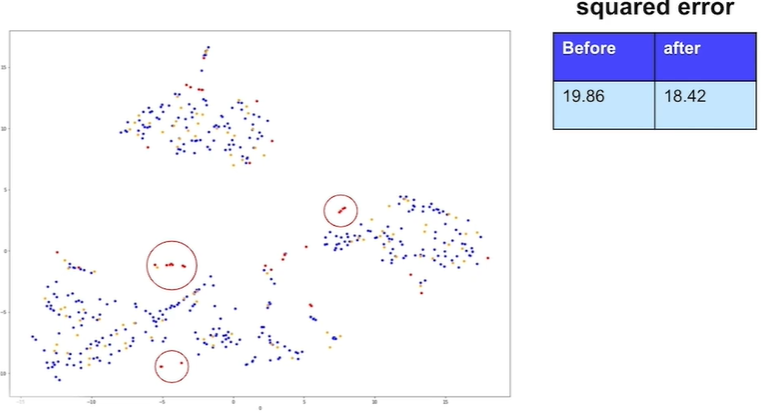
이상치가 train과는 겹치지만 test에는 겹치지 않으므로 이상치를 제거해야 모델 성능 향상됨(Squared error 줄어듦)
'Programming > Python' 카테고리의 다른 글
| 트리 모델, TabNet (0) | 2024.01.27 |
|---|---|
| 기본 개념 정리 2 (ML) (0) | 2024.01.16 |
| ETL (Extract, Transform, Load) with command-line tools (1) | 2024.01.03 |
| [DL] over(under)fitting 최적, Dropout, Callback (0) | 2023.09.20 |
| [ML] SGDClassifier (확률적 경사하강법 분류모형) (0) | 2023.09.17 |



