합성데이터(재현데이터, Synthetic data) 정의
실제 데이터 특성만 참조하여 실제 개인과 직접적 관련 없는 완전히 새로운 데이터셋 생성 기술
즉, 실제 데이터(Real data)와 통계적 특성이 유사하여, 실제 데이터 분석 결과와 유사한 결과를 얻을 수 있는 새로 생성된 가상 데이터
*** 통계적 특성을 포함해서 모방하는 가상 시뮬레이션된 데이터 "재현자료(Statistical Synthetic Data)"보다 큰 개념

모든 종류의 Generative Model(생성형 모델)은 Data Synthesizer이다.
*** 개인정보 일부 또는 전부 변형하는 비식별 처리(가명, 익명처리) 와 다른 개념
비식별 처리(가명 정보): 개인정보 일부 또는 전부 삭제, 대체하는 등 가명처리를 통해 추가정보 없이 특정 개인을 알아볼 수 없는 정보 -> 유용성은 높으나 개인식별 위험이 있어 보호법 적용 대상. 안전조치 필요
비식별처리(익명 정보): 보호법 불필요 -> 자유로운 활용 및 공개 가능 but 데이터 활용 가치 낮음


[유형]
Fully synthetic data(완전 합성데이터): 생성된 데이터가 모두 100% 가상 데이터
Partial synthetic data(부분 합성데이터): 일부 set, 속성, 변수 등을 선택하여 합성 데이터로 대체한 set.
ex) 다른 것은 그대로 두고, 공개가 어려운 민감한 데이터만 합성데이터로 대체하는 방식 등으로 활용
Hybrid synthetic data(복합 합성데이터): 일부 변수 값을 합성 데이터로 생성하고, 생성된 합성데이터와 실제 데이터를 모두 이용하여 또 다른 일부 변수값들을 도출하는 방법으로 생성된 데이터
[강점]
법적 제약(추가 동의, 보호 조치 등) 없이 활용 가능,
민감한 정보가 포함된 경우에도 안전한 활용 가능 -> 프라이버시 보호기술(PET, Privavy Enhancing Technology)
비용 효율성: 직접 데이터 구축보다 합성데이터 사용이 저렴
"이미지 1개 확보하는데 통상 6달러, 합성데이터는 6센트" - Paul Walborsky, co-founder of AI.Reverie -
모델 성능 향상: 데이터가 부족한 경우 합성데이터로 이를 극복
(단, 합성데이터 품질이 좋아야 함. 부족한 경우 부분 합성 데이터를 활용)
ex) 자동차 교통사고 영상 등 수집하기 어렵거나 불가능한 극단적 사례
ex) 설문조사 결측 데이터(답을 완료X 인 경우)
ex) 편향된 데이터로 학습된 AI 모델의 고도화가 필요할 때



합성데이터 생성 절차

1. 사전준비
활용 목적, 범위 설정: 원본의 변수, 관계, 분포 등 어떤 특성을 얼마나 보존?, 어떤 생성기법?, 유용성 안정성 어느 수준으로 검증? (필수 아님)
데이터 공급자-수요자 확인: 단, 대중공개 목적 등의 경우 수요자 특정 X
Ex) 공급자 = 수요자인 경우도 있음, 개인정보 처리 위탁계약 등을 통해 데이터 위탁받아 생성하는 경우도 있음
원본데이터 유형, 속성 검토(정형, 비정형;이미지 및 영상 등, 반정형): 합성데이터에 그대로 생성되거나 관련 특성 과도 보존의 경우 개인 식별추론 위험성 있는 개인정보 포함 여부 확인(개인식별자 여부), 극단값(특이값) 존재 여부 확인
원본데이터 사용시 적용되는 법률조항 검토

2. 합성데이터 생성
생성 모델 결정: 도구, 함수, 파라미터 등 결정
고려사항: 합성데이터 활용 목적 범위,원본데이터 특성, 생성모델 장단점, 한계, 개인식별 위험성, 전처리 후처리 필요여부
전처리: 합성데이터에 필요한 원본 데이터 추출 후 생성에 적합하도록 처리
개인식별자 및 특이값(극단값)처리: 제거 여부, 처리 방식은 선택 사항
생성에 필요한 경우 전처리 없이 그대로 활용하여 생성 후 위험을 점검하고 필요 시 후처리 진행
생성에 필요하지 않은 경우 해당 값을 삭제하거나 전처리(대체, 변환, 표본의 산포 줄이는 등)하여 활용
검토: 의도한 대로 생성되었는지 검토 (특정 속성 논리적 제한 여부; 키 몸무게 컬럼에 음수값이 존재하는지 등)
[합성 데이터 생성 방법 예제]
통계기반 모수적 기법: 원본의 통계적 분포를 가정하고 해당 분포에서 난수 생성
Gaussian Misture Model(가우스 혼합 모델): 모수인 평균과 표준편차에서 분포 추정 후 각 분포에서 난수 생성
가정: 원본 각 컬럼이 하나의 정규분포 모양이 아닌, 여러 정규분포가 혼합된 형태임

장점: 범주형 컬럼이 적고 연속형 데이터가 있는 경우에 효과적
단점: 정규분포 가정이 적합하지 않은 경우 정확도 낮음
통계기반 비모수적 기법: 분포 가정 없이 합성데이터 생성(모수적 기법의 분포 가정 위험을 줄인 방법)
Synthpop-CART: ML의 CART 알고리즘으로 원본을 이진트리(binary tree)에 저장 후 조건에 맞는 데이터를 조건부 확률 분포를 통해 순차적으로 생성
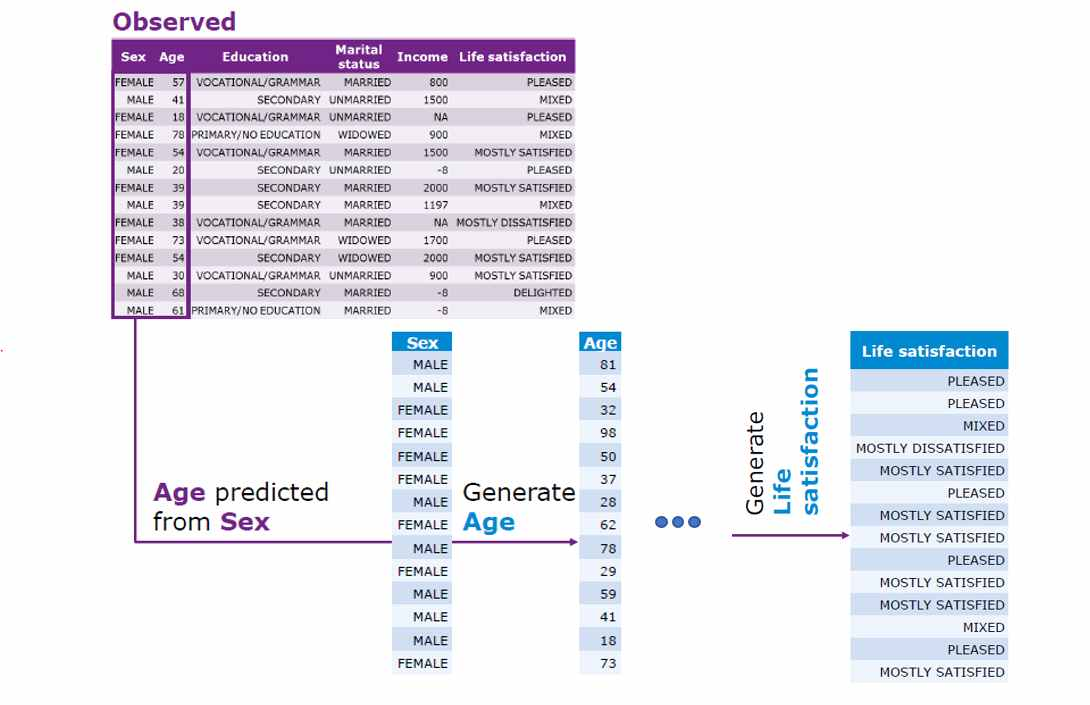
장점: 분포 가정에 따른 문제(모수적 기법)가 없음, 생성속도 빠름, 가장많이 사용되는 생성기법
단점: 원본을 트리에 넣고 샘플링하므로 원본과 같은 내용이 합성데이터로 생성될 가능성이 높음
AI(딥러닝) 기법: AI 기술 이용하여 합성데이터 생성
GAN(적대적 생성 신경망): 가짜 데이터 생성AI(Generator), 진짜 가짜 구분 AI(Discriminator)를 각각 만들고 두 AI가 경쟁하여 발전하는 방식


장점: 합성데이터 생성에 원본 참조가 없으므로 원본 그대로 생성될 우려 없음. 원본 데이터 복원 어려움(안정성 높음: 프라이버시 위험 낮음), 비정형 데이터 합성에 추천되는 방법
단점: 유용성 확보위한 정밀한 모형 작업 필요 -> 시간, 계산, 리소스 많이 요구
범주 + 수치로 이뤄진 복잡한 구조, 클래스 불균형 등이 존재하는 Tabular 데이터에는 부적합
-> CTGAN(Conditional Tabular GAN, Xu et al. 2019, NIPS) 사용: 조건부 확률분포를 이용해 GAN을 학습
StyleGAN: 이미지 생성을 위한 GAN(서로 대립하여 합성 이미지 생성), 낮은 해상도에서 해상도 점진적으로 높이는 훈련

-> 매핑 신경망(특정 스타일 벡터 생성), 합성 신경망(다양한 해상도 스타일 삽입), 가중치 변조, 복조 등을 통해 고품질 이미지 생성 유도
최근 GAN 모델 근황: CTAB-GAN (Zhao et al, 2021 ACML), CTAB-GAN+ (Zhao et al, 2024)
그외 VAE-based Synthesizer 연계:
• TVAE (Xu et al. 2019, NIPS): CTGAN과 같은 전후처리, VAE data synthesizer
• GOGGLE (Liu et al, 2023, ICLR) : Sparse network 이용
Diffusion Model: 여러 단계에 거쳐 노이즈 추가하는 확산 과정 후, 이를 복구하는 과정에 이미지 생성

Stable Diffusion: text to image 이미지 생성모델. 원본 이미지 확률분포 랜덤 샘플링으로 노이즈 조절하는 과정을 학습하여 합성데이터 생성

장점: txt-img 특화, fine-tuning으로 더 효과적 결과 출력 가능
단점: 모델 단독 학습으로 구축하는 데에 상당한 컴퓨터 자원, 시간 필요 -> mostly fine-tuning pre-trained model
그외 Diffusion Model-based Synthesizer:
• STaSy (Kim et al, ICLR 2023): Use Score-based generative models
• CoDi (Lee et al, ICML 2023): Use two diffusion models to separately model continuous and discrete variables
• TabDDPM (Kotelnikov et al, ICML 2023)
• TABSYN (Zhang et al, ICLR 2024): Diffusion model within the latent variable space of VAE
• Forest-VP (Jolicoeur-Martineau et al, ICML 2024): Score-based diffusion models, trained with gradient-boosted tree
Flow-based Synthesizer
• Forest-Flow (Jolicoeur-Martineau et al, ICML 2024): Trained with gradientboosted tree
Transformer-based Synthesizer
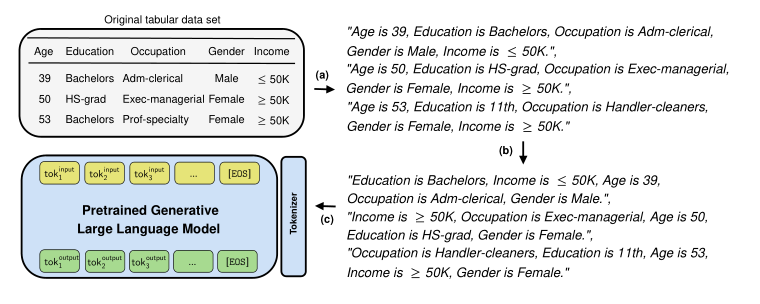
• TabMT (Manbir and Roysdon, NeurIPS 2024): Adopt the masked transformer, similar to what is used in BERT, to sequentially impute masked entries
• GReaT (Borisov et al., ICLR 2023): Use Transformer-based Large Language Models (LLMs) to create synthetic data
3. 검증
유용성 검증: 생성된 합성데이터가 원본과 얼마나 유사한지, 동일한 목표를 달성할 수 있는지 등을 검토
ex)
▪ 합성데이터가 원본 특징(분포, 각 컬럼의 상관관계 등)이 유사한지?
▪ 원본과 합성데이터를 사람이나 AI가 잘 구분 못하는지?
▪ 합성데이터를 학습한 AI모델이 원본 학습 모델과 유사한 성능인지?
안전성 검증: 생성된 합성데이터로 원본 데이터의 개인 정보가 식별 및 추론이 가능한지 등을 검토
ex)
▪ 합성데이터에 원본과 동일한 것(레코드)이 있는지?
▪ 합성데이터에 원본과 비슷한 특징이 과도하게 재현되거나 특이값(극단값) 등이 그대로 반영되어 원본데이터 내 개인을 쉽게 추론할 가능성이 있는지?
▪ 합성데이터 생성 모델이 무차별 매개변수 탐색 공격, 모델 공격 등 고도화된 적대적 공격(Adversarial Attack)을 통한 원본 유추 위험 없는지?
이 두 검증은 상충 관계(Trade-off)
-> 적절한 균형점을 찾아야 함 (하나를 올리면 다른 하나가 내려감)
-> 기준 충족될 때까지 데이터 재생성, 추가처리(삭제 및 조정), 재검증
[검증 방법]: 방법과 순서는 자율 선택
기준(지표, 지표별 임계값) 등을 설정하고 측정 비교 -> 기준 충족될때까지 계속 반복 수행
예제1) 비정형 합성데이터: 유용성 안전성 동시 검증 (기준 충족될때까지 재생성, 검증, 보완 과정 반복)
방법: 필요수량 이상으로 생성 후, 기준 미달 데이터 삭제, 부족하면 데이터 재생성 후 재검증 반복 수행
예제2) 정형 합성데이터: 안전성 -> 유용성 검증(안전성 충족된 것 중에서 유용성 높은 것 선택)
방법: 여러 다양한 생성모델 사용 -> 합성데이터 생성 -> 안전성 기준 충족 데이터 선정 -> 유용성 높은 데이터 선정
[임계값 설정법]: 데이터 별 특성을 고려하여 임계값 설정. (절대적 임계값 없음)
1) 유용성 우선

2) 안전성 우선

3) 생성된 합성데이터 지표가 기존 분포에서 얼마나 벗어났는지 측정 (통계학 가설검정 유사 원리)
지표 설정: 원본데이터의 일부분을 완벽한 합성데이터로 간주하고 지표를 여러 번 계산하여 지표 분포 측정
-> 해당 임계값 만족 = 원본데이터 준하는 지표 충족 판단 가능
[비정형 데이터 유용성 검증 지표]: 참고용이며 개선 및 변경 혹은 다른 방법 사용 가능
1) 모델 성능 검증: 합성데이터가 원본과 동일한 성능을 내는지 검증 (F1 score, 정확도 지표 등)
정형데이터에도 사용 가능!

검증 방법: 원본 데이터로 학습한 모델과 합성데이터로 학습한 모델 성능 차이 비교하여 그 차이가 임계값(예시 5%)보다 작으면 유용성 검증 통과
2) Visual Turing Test(VTT): 관련 전문가 대상으로 원본과 합성이미지 동일한 수로 무작위 선별하여 구성한 샘플에서 원본을 구분하는 테스트를 수행하고 정답률(=바르게 예측한 샘플 수 / 전체 샘플 수) 측정

예시 임계값: 정답률 50%가 이상치. 유용성 우선시, 오차허용 10%적용하여 40~60%가 임계값.
안전성 우선시, 오차허용 20% 적용하여 30~70%가 임계값.
3) 이미지 품질 검증: 원본과 합성이미지 데이터 분포 거리 비교 -> 학습과 원본의 분포 유사도 검증
방법: 원본과 합성이미지 특성 추출하여 수치화한 후, FID(Frechet Inception Distance)값이 임계값보다 작으면 통과


임계값 설정방법(예시): 유용성 우선(방법1) 사용(구하는 지표는 FID값)
[정형데이터 유용성 검증 지표]
1) 2차원 관계 유사성: 원본과 합성데이터 각 컬럼 간의 상관관계 행렬 차이값의 표준편차 계산
임계값: 활용 목적, 개별 데이터셋 별로 적절한 임계값 선정.

※ 값이 작을수록, 0에 가까울수록 유용성 높음
검증 방법: 합성데이터 상관계수 표준편차가 설정한 임계값보다 작으면 유용성 검증 통과
2) 구별 불가능성: AI가 원본과 합성데이터를 구분하지 못하는 지점을 정량적 측정. 즉, 원본과 합성데이터를 섞은 데이터셋에 원본을 구별하는 ML 모형을 만들고, 정확도가 1/2이하면 높은 수준의 유용성을 가진다는 의미
임계값: 활용 목적, 개별 데이터셋 별로 적절한 임계값 선정.

pi: i번째 레코드를 합성데이터로 예측할 확률
※ 값이 작을수록, 0에 가까울수록 유용성 높음
검증 방법: 합성데이터 pMSE값이 설정한 임계값보다 작으면 유용성 검증 통과
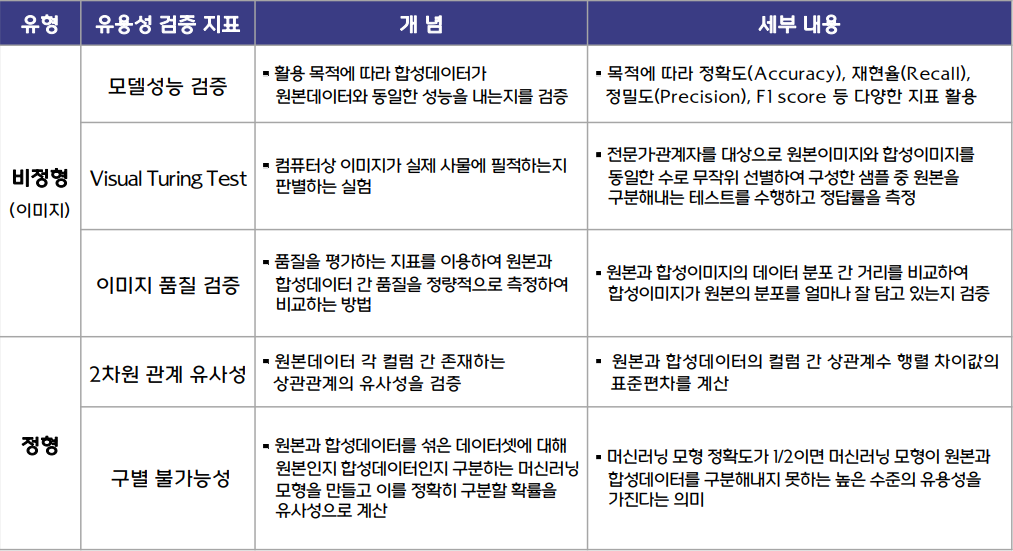
[비정형 합성데이터 안전성 검증 지표]
1) 생성과정 검증: 합성데이터 생성과정 검토; 원본 데이터 복원이 어렵거나 불가능한 합성데이터 생성 모델을 선택했는지 여부, 적절한 전처리 수행여부, 개인정보가 포함된 데이터 처리 방식 검토, 비가역적 알고리즘(사전 딥러닝 모델)사용 여부 등
생성방법 검토: 적절한 비가역적 알고리즘(styleGAN 등) 사용여부, 완전 합성 방식 이미지 생성방법 사용 여부 확인
전처리 검토: 메타데이터 처리 여부(삭제 or 비식별화), 합성에 불필요한 데이터 영역 삭제 여부
2) 구조적 유사성 검증: 휘도, 대조, 구조 등을 기반으로 원본-합성이미지의 형태적 유사성 측정
SSIM(Structural Similarity Index Measure) 지수: 이미지의 구도, 휘도, 대비를 하나의 품질 점수로 통합한 지표
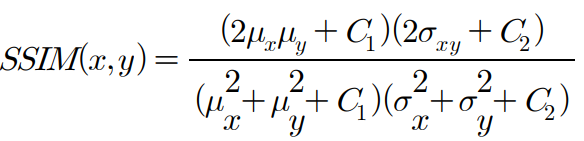
※ 이미지가 유사할수록 1에 가까워짐
개별 데이터셋 별로 적정한 임계값을 산출
1) 원본데이터를 일정한 크기로 임의분할하여 A데이터셋과 B데이터셋으로 구성
2) A를 원본, B를 합성데이터로 가정한 후 SSIM을 측정하는 과정을 100회 반복
3) 누적된 측정값의 95분위수를 정해 임계값으로 산출

3) 지각적 유사성 검증: 사람의 시각인지능력 측면에서 원본-합성 이미지 간 시각적 유사성 측정
LPIPS(Learned Perceptual Image Patch Similarity) 지수 값 사용

※ 유사할수록 1에 가까워짐
개별 데이터셋 별로 적정한 임계값을 산출
1) 원본데이터를 일정한 크기로 임의분할하여 A데이터셋과 B데이터셋으로 구성
2) A를 원본, B를 합성데이터로 가정한 후 LPIPS을 측정하는 과정을 100회 반복
3) 누적된 측정값의 95분위수를 정해 임계값으로 산출

4) 주관적 검증: 전문가-관계가자 합성이미지 원본 유사성, 개인식별성 등 직접 검수(정성평가)
-> 다양한 형태, 예상치 못한 요인을 막기위해 사람의 주관적 검증 도입
검증 방법: 구조적, 지각적 유사성이 높게 측정된 이미지 등에 대해서만 선별 검사하고, 적절치 않다고 판단된 이미지 삭제
[정형 데이터 안전성 검증 지표]
GDPR(General Data Protection Regulation) Art.29 WP Opinion 익명화 단계 필수 고려 위험 3가지
1) 식별 위험도: Is it still possible to single out an individual?
합성데이터(레코드)가 원본에 동일하게 존재할 확률 측정 -> 같은 경우 합성데이터 내 레코드 삭제

※ 값이 작을수록, 0에 가까울수록 유용성 높음
검증 방법: 합성데이터 식별 위험도가 설정한 임계값(개별 설정)보다 작으면 안전성 검증 통과
2) 연결 위험도: Is it still possible to link records relating to an individual?
공격자가 원본 준식별자(K)와 같은 값을 갖는 레코드를 찾았을 때, 민감정보(T)까지 유추할 비율
T변수값이 다양하지 않으면 위험이 크다는 의미.
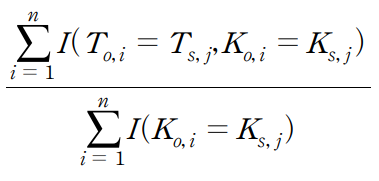
※ 값이 작을수록 안전성 높음.
검증 방법: 합성데이터 연결위험도(TCAP값)가 설정한 임계값(개별 설정)보다 작으면 안전성 검증 통과
임계값 기준보다 크면 해당 레코드 삭제 가
3) 추론 위험도: Can information be inferred concerning an individual?
원본과 같은 데이터는 없지만 유사한 레코드가 많아 출처를 추론(authenticity)할 가능성 높은지 여부 측정

ds<do 비율을 지표로 사용
※ 값이 높을수록 안전성 낮음, 추론 위험이 없을 때 0.5가 이상값
검증 방법: 합성데이터의 추론 위험도가 설정한 임계값(개별 설정)보다 작으면 안전성 검증 통과

그외 최신 평가지표: DOMIAS (검색이 잘 안됨..) 등
4. 활용
적정성 심의: 과정 및 결과에대해 객관적, 전문적 검토가 필요할 경우, 전문가 등 통해 적성성 심의 가능.
단, 우려사항이 해소되었다고 판단 시 생략 가능

안전 관리: 설정한 합성 데이터 목적, 범위에 맞게 활용되도록 관리.
이용 계약 등으로 활용에 제약이 있는 경우 관리체계 필요
유용성 위주, 안전성이 낮은 합성데이터는 일정한 통제 필요할 수도 있음
5가지 예제 적용 사례(상세 내용은 해당 게시물에서 확인)

데이터 배포: 가명정보 지원플랫폼
가명정보 지원 플랫폼
가명처리·결합의 활용사례를 확인해보세요. 가명정보 지원 플랫폼은 가명처리 및 가명정보 결합을 지원하여 데이터를 안전하고 유용하게 활용할 수 있습니다.
dataprivacy.go.kr
누구나 신청 가능, 최소한의 확인 절차를 거쳐 제공
한계점 및 향후 과제
합성데이터: 기술발전 초기단계 -> 정형화, 단일화된 생성 검증 방법 제시 어려움
-> 5가지 예제(충치판별, 안전모, 혈당정보, 멤버십 사용내역, 주주 정보)는 방식 중 하나를 제시. 표준이 아님
-> 합성데이터 활용 실사례 발굴 및 축적을 통해 생성방법, 검증방식에 대한 상세지침 마련 필요
5가지 예제에서 다루지 않은 비정형 데이터 적용 문제: 영상, 자연어(text), 음성 등
-> 비정형 데이터를 합성데이터로 생산도 어렵지만, 전통적인 통계 기법으로 유용성, 안전성 평가하는 것도 어려움
-> 연구 필요
개인정보 기반 합성데이터가 익명성 검증 없으면 법적 제약(보호법 등)으로 활용 부담 발생
-> 익명정보 활용 사례 확산되도록 익명성 판단기준, 체계 마련 필요
합성데이터 인식 부족, 복잡한 생성 절차, 고도의 전문성 및 기술 요구 -> 활용의 걸림돌
-> 합성데이터 생성 활용 사례 및 기반 서비스 등을 발굴, 홍보하여 기술 이해도 및 적용 가능성 제고 필요
'TechStudy > SyntheticData' 카테고리의 다른 글
| 합성데이터 사례: 기업개요 및 주주 신용등급 (0) | 2024.06.18 |
|---|---|
| 합성데이터 사례: 통신사 멤버십 사용내역 (0) | 2024.06.18 |
| 합성데이터 사례: 혈당 측정정보 (0) | 2024.06.18 |
| 합성데이터 사례: 안전모 착용 감지 AI 솔루션 (0) | 2024.06.18 |
| 합성데이터 사례: 구강 이미지를 통한 충치 진단 AI 솔루션 (0) | 2024.06.17 |



