설치 및 실행
pip install pandas # 또는 프롬프트보다는 !conda install pandas, !pip install pandas
# 아나콘다는기본 설치이므로 별도 설치 필요 X
import pandas as pd #pd로 약칭화
DataFrame (표) 만들기 -> pd.DataFrame(2차원리스트, columns=컬럼리스트, index=인덱스리스트)
Create the table from the List format)
df = pd.DataFrame([
['james',30,'programmer'], #개수만큼 순서대로 하나씩
['amy',20,'student'],
['david',25,'designer'] ],
columns=['name','age','job'], # 칼럼이름
index=['a','b','c'] # 행 이름
)
df또는 변수 지정
basic = [['james',30,'programmer'],
['amy',20,'student'],
['david',25,'designer']]
df = pd.DataFrame(basic, columns = ['name', 'age', 'job'], index = ['a', 'b','c'])
df
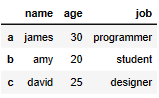
Create the table from the Dict format)
df = pd.DataFrame(
{'name':['james','amy','david'], # key = 칼럼이름 value = 값
'age':[30,20,25],
'job':['programmer','student','designer']
},
index=['a','b','c'] # 행 이름
)
df또는
dict = {'name':['james','amy','david'], # dict 변수 지정
'age':[30,20,25],
'job':['programmer','student','designer']
}
df = pd.DataFrame( dict, # 변수로 바로 출력
index=['a','b','c'] # 필요한건 행 이름(index) list 뿐
)
df
Create the table from the CSV file outside)
df = pd.read_csv('data/scores.csv') #csv file must be utf-8 format.
df # 경로는 해당 ipynb 실행한 경로 기준이 현 위치!
기본 데이터 열람법 (위 df = pd.read_csv 상태에서)
head(n) -> n행만큼 윗부분 출력 * n 생략시; head() -> 기본 5행 출력
tail(n) -> n행만큼 뒷부분 출력
sample(n) -> n개만큼 랜덤행 출력
df.head(3)
df.tail() # 5행 출력
df.sample() # 랜덤 1개 출력
nlargest(n, 'name') -> n개만큼 name 칼럼의 높은 순으로 출력
nsmallest(n,'name') -> n개만큼 name 칼럼의 낮은 순으로 출력
df.nlargest(5,'eng') # eng칼럼 높은순으로 5개 출력
df.nsmallest(5,'eng') # eng칼럼 낮은순으로 5개 출력
df.shape -> 데이터 크기 조회 ex) (30, 4)
len(df) -> 데이터 개수 조회 -> ex) 30
df.columns -> 컬럼명 조회 -> ex) Index(['name', 'kor', 'eng', 'math'], dtype='object')
df.index -> 인덱스 조회 -> ex) RangeIndex(start=0, stop=30, step=1)
df.dtypes -> 자료형 조회
-> ex)
name object
kor float64
eng float64
math float64
dtype: object
df.info() -> 정보 조회 (샘플, 칼럼, 각 별 정보 확인) 주로 non null 여부, type, 컬럼정도만 확인.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30 entries, 0 to 29
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 30 non-null object
1 kor 27 non-null float64
2 eng 28 non-null float64
3 math 29 non-null float64
dtypes: float64(3), object(1)
memory usage: 1.1+ KB
df['name'].value_counts() -> 특정 칼럼 정보만 조회 -> ex) df['kor'].value_counts()
100.0 8
90.0 6
70.0 5
95.0 3
80.0 3
50.0 2
Name: kor, dtype: int64
df.describe() -> 전반적 요약 통계 조회 (개수 평균 중간값 등)

Ex)
df['name'].mean() -> 특정 칼럼 특정치만 조회 -> ex) df['kor'].mean()
-> 85.74074074074075
컬럼명 기반 데이터 추출하기 (대괄호 안 list형태 칼럼 들어감. 대괄호 2개여야함)

# 'name','kor' 컬럼 데이터 추출하기
df_name_kor = df[['name','kor']]
df_name_kor.head(3)
# 'math' 컬럼을 데이터프레임 형태로 추출하기
df_math = df[['math']]
df_math
# type
type(df_math)pandas.core.frame.DataFrame
조건에 따른 데이터 추출(bool 타입)
# kor 점수가 100점인 데이터 불린인덱스
df['kor']==1000 True
1 False
2 False
3 True
4 False
5 False
6 False
7 False
8 False
9 True
10 False
11 False
12 True
13 False
14 False
15 True
16 False
17 False
18 False
19 False
20 True
21 False
22 False
23 True
24 False
25 False
26 True
27 False
28 False
29 False
Name: kor, dtype: bool
bool 형태로 데이터 추출
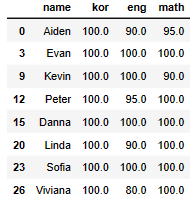
# kor 점수가 100점인 데이터 추출
df[df['kor']==100]
조건이 여러 개인 경우 논리 연산자(&, |, ~, ~=) 기준으로 ()로 나뉨
note:: & : and | : or != : not equal ~ : not
# 한 과목이라도 100을 받은 학생 추출
df[(df.kor==100)|(df.eng==100)|(df.math==100)]# kor의 값이 60~90인 학생의 name, kor 추출
df[(df['kor']>=60)&(df['kor']<=90)][['name','kor']]
특정 값인 경우만 추출 .isin([ 칼럼 ]) <- ~리스트에 해당하는 조건
# 이름이 Amy인 데이터 추출
df[df['name'].isin(['Amy'])]
# 이름이 Amy, Rose인 데이터 추출
df[df['name'].isin(['Amy','Rose'])]
# kor이 50,100 데이터 추출
df[df['kor'].isin([50,100])]
컬럼.isnull() -> null인 것만 추출
컬럼.notnull() -> null아닌 것만 추출
# kor이 null인 데이터 추출
df[df.kor.isnull()]
# kor이 null이 아닌 데이터 추출
df[df.kor.notnull()]
'Programming > Python' 카테고리의 다른 글
| [Pandas] 데이터 추출(loc, iloc) (0) | 2023.08.29 |
|---|---|
| [Pandas] Series (0) | 2023.08.29 |
| [Python] API(json, xml) (1) | 2023.08.22 |
| [Python] web scraping (0) | 2023.08.21 |
| [python] 문자열 편집, 절대경로 상대경로, 데이터 읽고 처리 (1) | 2023.08.21 |


