pivot()에서 함수가 들어가야하는 경우 pivot_table을 사용해야한다.
[구조]
pd.pivot_table(데이터프레임, index=인덱스, columns=컬럼, values=집계할데이터, aggfunc=통계함수)
aggrunc의 디폴트는 mean

이와 같은 데이터 표 예제에 대해서
[잠깐 note]
fill_value = 0 <- pivot table중 하나의 옵션. float입력시 null있는 곳만 float
나머진 int로 변환
fillna(0) <- 함수. 원본을 건드리지않고 null 대체값 입력한것으로 type 보존

# item, size별 재고 합계
df.pivot_table(index='item', columns='size', values='inventory', aggfunc='sum')
# [item,color], size별 재고 합계
df.pivot_table(index=['item','color'], columns='size', values='inventory', aggfunc='sum')
# null값은 0으로 처리
df.pivot_table(index=['item','color'], columns='size',
values='inventory',
aggfunc='sum', fill_value=0)

# [item,color], size별 판매,재고 합계
df.pivot_table(index=['item','color'],
columns='size',
values=['sale','inventory'],
aggfunc='sum',
fill_value=0)
[문제풀이 예제]


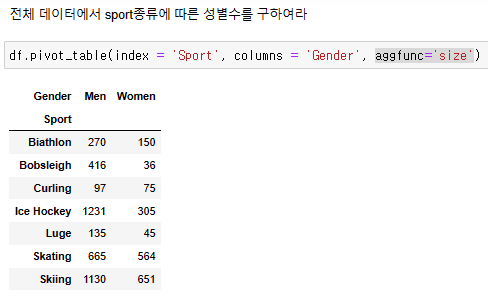
aggfunc = 'size' <- value 지정 따로 없이도 알아서 각 종목별로 세주는 함수
fill_value=0 <- null 값 처리

[타이타닉 성별, 객실등급별 생존분석 예제]

Survived = 0 : 죽음
Survived = 1 : 생존
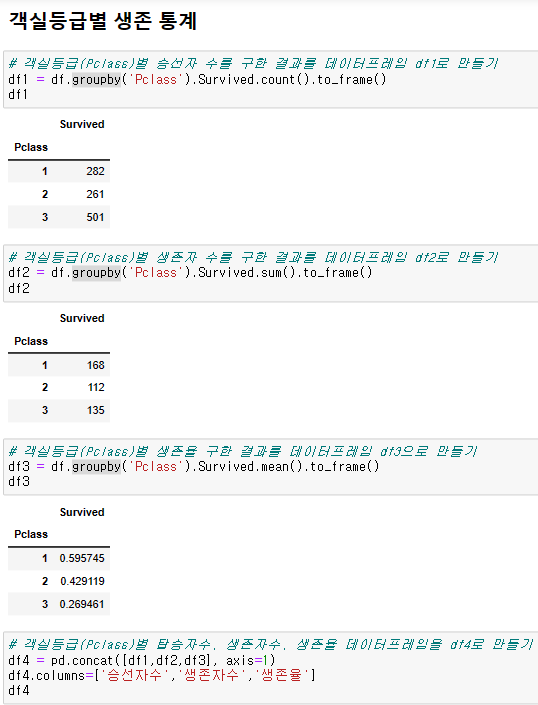
성별, 객실등급별 승선자 수 -> count함수로 전체 count

df_titanic.pivot_table(index='Sex',
columns='Pclass',
values='Survived',
aggfunc='count', #<-여기에 지정
margins=True)margins = True: 그룹별 부분합, 총합계 표시 여부
성별, 객실등급별 생존자 수 -> sum으로 특정 조건만 sum 유도.

df_titanic.pivot_table(index='Sex',
columns='Pclass',
values='Survived', #생존자로 한정
aggfunc='sum',
margins=True)
성별, 객실등급별 생존율 -> survived value 해당 구간 전체 평균값 (mean)

df_titanic.pivot_table(index='Sex',
columns='Pclass',
values='Survived',
aggfunc='mean', #<-이게 default라서 생략 可
margins=True)aggfunc 생략은 default로 mean 함수 실행. 따라서
df_titanic.pivot_table(index='Sex',columns='Pclass',values='Survived', margins=True)이와 같이 생략한 코드도 동일한 결과물 출력.
- df.groupby(그룹기준컬럼).통계적용컬럼.통계함수
- count() : 누락값을 제외한 데이터 수
- size() : 누락값을 포함한 데이터 수
- mean() : 평균
- sum() : 합계
- std() : 표준편차
- min() : 최소값
- max() : 최대값
- sum() : 전체 합
count 사용
sum 사용
mean 사용
위 3개를 정리해서 합치기
df.columns로 컬럼이름 변경



- 데이터프레임.groupby(그룹기준컬럼).groups --> 그룹별 인덱스:[데이터리스트] 출력
- 데이터프레임.groupby(그룹기준컬럼).get_group(그룹인덱스) --> 그룹별 인덱스에 해당하는 데이터프레임 출력

[문제풀이]




데이터중 neighbourhood_group 값이 Queens값을 가지는 데이터들 중 neighbourhood 그룹별로 price값의 평균, 분산, 최대, 최소값을 구하라
df[df['neighbourhood_group']=="Queens"].groupby(['neighbourhood']).price.agg(['mean','var','max','min'])df로 기존에 배운 특정조건 뽑아내기를 섞는 문제이다.
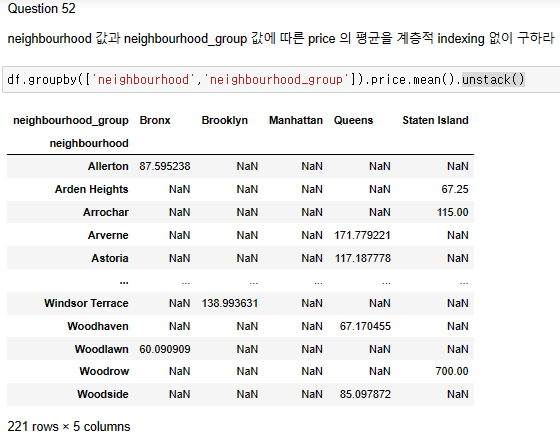
데이터중 neighbourhood_group 값에 따른 room_type 컬럼의 숫자를 구하고 neighbourhood_group 값을 기준으로 각 값의 비율을 구하여라
Ans = df[['neighbourhood_group','room_type']].groupby(['neighbourhood_group','room_type']).size().unstack()
Ans.loc[:,:] = (Ans.values /Ans.sum(axis=1).values.reshape(-1,1))
Ans
코드 상세 설명>>
Ans.loc[:,:] = (Ans.values /Ans.sum(axis=1).values.reshape(-1,1))loc[: , :] <- 전체 선택.
Ans.values -> 표의 숫자값만 행렬로 출력 mtx(5*3)
Ans.sum(axis=1) -> 1열 5행으로 각 행의 합 mtx(5*1) 출력
reshape(-1,1) <- numpy 함수. 행렬 형태 변형 서로 연산되게끔 변형 (5*3mtx 1*5mtx)
'Programming > Python' 카테고리의 다른 글
| [Matplotlib] 히트맵(pcolor) 및 응용 (0) | 2023.09.05 |
|---|---|
| [Matplotlib] 기본 (0) | 2023.09.04 |
| [Pandas] row <-> col by melt, pivot and transpose (0) | 2023.08.30 |
| [Pandas] concat, merge로 데이터 연결 (SQL JOIN개념) (0) | 2023.08.30 |
| [Pandas] type 확인 및 변환 (1) | 2023.08.30 |



