지도학습 : target(y) 有 ex) Linear regression(선형회귀: 규제; 라소/릿지/엘라스틱 넷 기법)
Logistic regression -> Decision tree(결정나무; random forest, cart)
그 외 알고리즘 종류들 knn, kmeans
비지도학습 : target 無 ex)
반 지도학습(강화학습): 보상을 통해 계속 학습 유도. ex) 알파고

Machine Learning(ML) 알고리즘 구현한 오픈소스 라이브러리 중 유명한 것 하나.
일관. 간결한 API. 문서화 잘되어있음.
알고리즘 -> python class. Data set -> numpy 배열, Pd (df), Scipy 등
데이터 표현 용어
*sample(표본) = Matrix row ex) n_samples 개별객체
*feature(특징) = Matrix column ex) n_features 개별관측치
Target vector: 특징행렬(x)로부터 예측하고자하는 값의 벡터 (= 종속변수, 출력변수, 결과변수, 반응변수)

예제>>
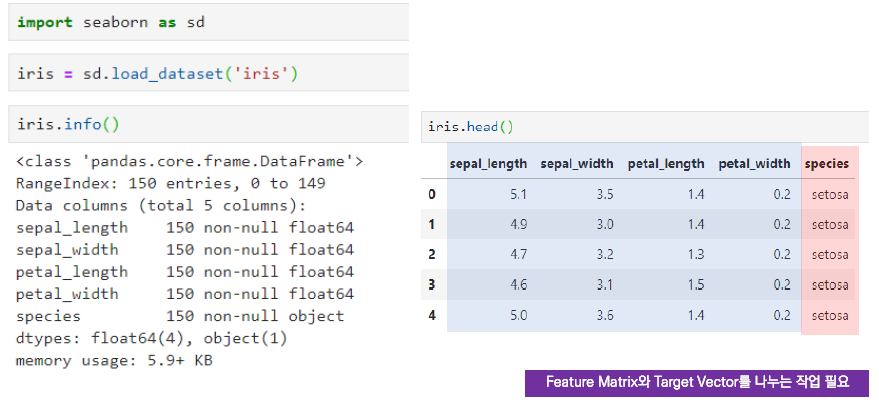

<<Scikit_learn을 사용하는 방법 예제>>
Random(np)의 randomstate: 하나 10개 값 임의로 고정하는 것. rand(개수) 임의 개수 100개

해당 모양은 단순하므로 Linear regression이 可

Numpy의 reshape(-1, 숫자) <- -1은 알아서 x에 맞게 배열하라는 의미이다.

x,y에 맞는 선형회귀 모델을 fit()함수로 학습 (estimate 형태 최적화)
coef = x의 계수 (coefficient) = 기울기

예측값 생성은 predict함 사용
np.linspace(구간시작,구간끝, num=개수) : 특정구간 균일하게 개수 형성
-1부터 11구간사이에 100개 균일하게 생성

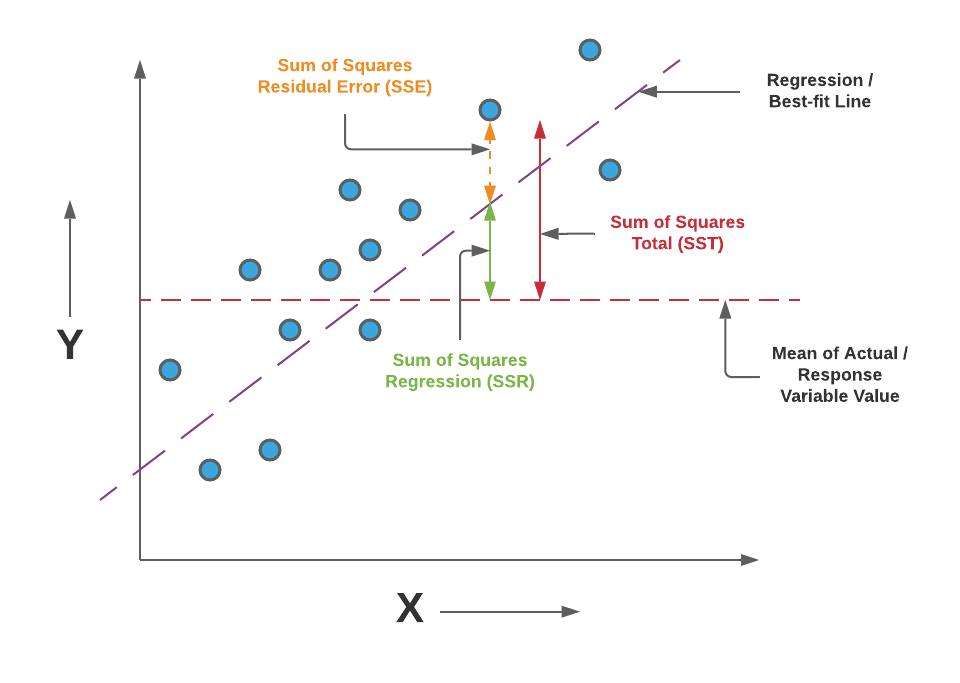
MSE(mean square error) 점검 (=y값과 y prediction과의 차이 점검)
(잠깐 MSE 개념 점검!!)

It assesses the average squared difference between the observed and predicted values.
When a model has no error, the MSE equals zero. As model error increases, its value increases.
MSE는 모든 점과 선과의 거리 평균값 (에러 평균값)
그냥 개별점과 선의 거리는 residual error이다.
'Programming > Python' 카테고리의 다른 글
| [ML] Cross Validation(CV; 교차검증), Grid Search (1) | 2023.09.07 |
|---|---|
| [ML] 기본 데이터 정리 및 split (iris 예제) (1) | 2023.09.06 |
| 데이터 전처리3 (Correlation) (0) | 2023.09.05 |
| 데이터 전처리2 (Data Scaling) (0) | 2023.09.05 |
| 데이터 전처리1 (null, outlier, bias, regression) (0) | 2023.09.05 |



