○ 목적: LoRA로 파인튜닝한 모델을 스스로 참조하는 형태로 독립시키는 것.
-> LoRA로 파인튜닝했어도 원본 모델과 merge를 함으로써 참조가 불필요하도록 모델 독립
원인: 효율적인 속도 및 연산을 위해 조절, 변경한 LoRA matrices만 저장되기 때문
○ huggingface에 모델을 (비공개) 업로드하면 모델 독립이 자동으로 이뤄질까?

-> _name_or_path에 아무 문자열이나 넣어도 정상 작동하므로 모델 독립이라 판단 가능
- 로드 시간: 약 6초 이내로 로드 완료
- 모델 작동 여부: 허깅 기반 로드이므로 답변 속도는 10초 이내로 빠름
-> 문제점: 허깅에 공개적으로 업로드했다는 것(로컬 모델 개발 목적에서..)
(* 단, 허깅에 업로드한 모델은 private로 비공개 설정이 가능하다.)
○ LoraConfig를 조절하는 옵션을 담은 Peft 라이브러리에 방법이 있을까?
-> 공식 문서에 따르면 modules_to_save라는 옵션이 있음. 그러나 본 노트의 목적과 다른 용도로 판단됨
○ KULLM(구름)이 사용한 merge 방법 시도
- KULLM: 고려대학교에서 만든 GPT_NeoX 구조의 LLM 모델
-> 결과: Llama3이 GPT_NeoX 구조가 아니므로 실패
○ 모델 merge kit를 사용해야 할까?
- model merge: 2개 이상의 LLM을 GPU없이 하나의 모델로 합치는 것 -> 일단 참고용으로 인지
참조 링크: https://github.com/arcee-ai/mergekit, 설명문서
○ model.save_pretrained에 safe_serialization=True로 옵션 설정하여 적용하기
- 과정: 저장과정에서 생긴 config.json, adapter_config.json 두 파일의 base model path를
학습 base model인 bllossom이 아니라 자기 자신 (Llama-3 ORPO) 참조하도록 변경
-> safetensor와 함께 저장되어 안정적인 파인튜닝 모델 로드(6초) 가능
-> 기존 참조 Bllossom 모델의 파일명을 변경(경로변경)하여도 정상 작동
-> Bllossom 모델로부터 독립한 파인튜닝 모델로 판단됨
[특이사항]
○ 기존 Bllossom 모델의 생성 시간보다 빠른 경우는 기존 모델의 safetensor는 7개(31GB)
100개 농사로를 학습한 튜닝 모델은 2개(약 8GB) 정도로 모델 용량이 줄어들었을 때 나타남.
-> 모델이 경량화 되었는지, loss가 커진 것인지는 판단 불가.
-> 이 덕분에 메시지 생성시간이 매우 빨라진 것으로 추정
○ tokenizer와 model를 다시 로드하는 재정의 작업을 거치고 merge하면 약 16GB로 저장됨
검증
○ 의문점: 30GB에서 16GB로 용량이 약 절반으로 줄어든 100개 sample ORPO 튜닝 모델은
원본 모델의 성능 저하 없이 용량만 줄어든 것일까?
○ 모델 구조 비교: print(model) 방식으로 구조 출력하여 비교
| base model(llama-3-8b-KrBllossom) | ORPO tuned model |
| LlamaForCausalLM( (model): LlamaModel( (embed_tokens): Embedding(145088, 4096) (layers): ModuleList( (0-31): 32 x LlamaDecoderLayer( (self_attn): LlamaSdpaAttention( (q_proj): Linear(in_features=4096, out_features=4096, bias=False) (k_proj): Linear(in_features=4096, out_features=1024, bias=False) (v_proj): Linear(in_features=4096, out_features=1024, bias=False) (o_proj): Linear(in_features=4096, out_features=4096, bias=False) (rotary_emb): LlamaRotaryEmbedding() ) (mlp): LlamaMLP( (gate_proj): Linear(in_features=4096, out_features=14336, bias=False) (up_proj): Linear(in_features=4096, out_features=14336, bias=False) (down_proj): Linear(in_features=14336, out_features=4096, bias=False) (act_fn): SiLU() ) (input_layernorm): LlamaRMSNorm() (post_attention_layernorm): LlamaRMSNorm() ) ) (norm): LlamaRMSNorm() ) (lm_head): Linear(in_features=4096, out_features=145088, bias=False ) |
LlamaForCausalLM( (model): LlamaModel( (embed_tokens): Embedding(145088, 4096) (layers): ModuleList( (0-31): 32 x LlamaDecoderLayer( (self_attn): LlamaSdpaAttention( (q_proj): lora.Linear( (base_layer): Linear(in_features=4096, out_features=4096, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.05, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=4096, out_features=16, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=16, out_features=4096, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() ) (k_proj): lora.Linear( (base_layer): Linear(in_features=4096, out_features=1024, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.05, inplace=False) ) ... <<v_proj, o_proj, mlp의 로라 구조 중략>> (norm): LlamaRMSNorm() ) (lm_head): Linear(in_features=4096, out_features=145088, bias=False) ) |
- 차이점: ORPO는 단순 linear 사용이 아닌 LoRA 기반의 linear 레이어를 사용함
-> 일부만 파인튜닝한 모델이므로 LoRA가 사용됨
○ 각종 평가지표를 곁들인 비교
- 평가에 사용된 text 데이터: 문장 3개 (영어 문장 2개, 한글 문장 1개)
| 평가지표 | base model(llama-3-8b-KrBllossom) | ORPO tuned model |
| Model Size 모델 파일 크기 |
약 30GB | 약 16GB |
| Inference Time 추론 시간 |
평균 4.6668 ± 0.2050초 | 평균 5.2161 ± 0.2462초 |
| Memory usage 메모리 사용량 |
12131.52 MB | 12131.52 MB |
| Perplexity score | 72.2782211303711 | 72.26553344726562 |
- 파일 크기: 새 모델 용량이 적음 -> 저장 공간 절약 및 모델 메모리 로드와 네트워크 전송 시간 단축 효과
- 추론 시간: 10번 추론에 대한 평균 시간을 기록하였다. -> 기존 모델이 더 빠르다.
- 메모리 사용량: 차이 없음
- Perplexity: 이는 엄밀히 따지면 튜닝모델이 미세하게나마 더 좋음.
그러나 두 모델 성능 차이가 없다는 해석도 가능
○ 유의점: 평가에 사용된 text 데이터가 매우 단순하여 제대로 된 평가가 아닐 수 있음
[참고: Perplexity score(PPL)]
○ 정의: 모델이 주어진 텍스트를 얼마나 잘 예측하는지 측정하는 지표.
Perplexity is a measure of how well a probability distribution or probability model predicts a sample. It's a widely used metric in natural language processing (NLP) and information theory.
○ 해석 방법: 낮을수록 예측 성능이 좋음을 의미. 점수가 1인 경우, 모든 단어를 100% 예측한 이상적인 상태
주로 절대 평가보다는 모델 비교를 통한 상대 평가로 사용되는 지표.
○ 계산 방법: 문장(W)에 대한 generation probability 역수의 기하평균
즉, 문장 생성 확률의 역수를 단어의 수(N)으로 정규화
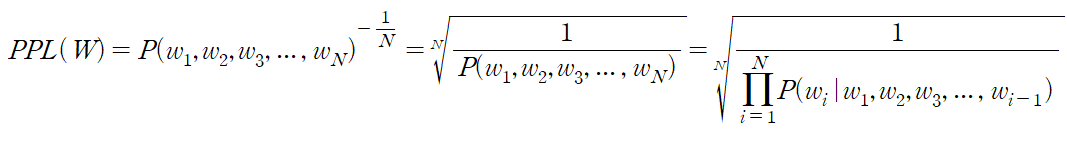
○ 한계점: 일관성, 관련성 또는 맥락 이해와 같은 측면을 평가하지 못함
결론
○ ORPO tuned sample 모델은 단순한 sample text 데이터 기반 평가 기준으로 볼 때,
LoRA가 원본 모델의 성능을 최대한 보존하면서 모델을 압축한 결과로 판단됨
○ Unsloth 환경에서 작업하는 경우에 원본 모델 저장 방법은 다음 코드를 실행
model.save_pretrained_merged("경로/모델이 저장될 파일 이름", tokenizer, safe_serialization = None)
단, 저장 과정에서 GPU 사용이 적지 않으므로 GPU 여유가 없는 상태에서 실행시 에러 발생.
'TechStudy > LLM' 카테고리의 다른 글
| 고급(?) 파인튜닝 기술 Reranker (0) | 2024.06.12 |
|---|---|
| LoRA? 신 기술 MoRA를 사용해보자! (0) | 2024.06.11 |
| Unsloth 환경을 도입하고 ORPO 파인튜닝(fine-tuning)하기 (0) | 2024.06.07 |
| Llama3, 그리고 ORPO (0) | 2024.06.04 |
| Llama3 and ORPO (리딩용) (0) | 2024.05.13 |



