
Unsloth(Unoptimized but Speeded LOssless Tuning Helper)?
○ 목적: LLM 파인튜닝을 casual mask를 이용하여 더욱 빠르고 효율적으로 해주는 오픈소스 라이브러리
링크: https://github.com/unslothai/unsloth
○ 특이사항

- 기본 오픈소스 무료 라이브러리 외에 더 좋은 성능을 광고하는 유료 라이브러리도 존재
- unsloth으로 파인튜닝한 모델은 스티커 사용 가능 (필수 아님)

Unsloth 도입 이유 및 사용 방법
○ 도입 이유
- Llama3(8B)기반의 ORPO를 같이 사용 가능
- 컴퓨터 사용 자원 감소 및 시간 절약 효과
-> 기존 ORPO만 사용한 것보다 메모리 사용량을 줄이고 상대적으로 빠른 fine-tuning을 수행
-> 메모리 사용량(main GPU cuda 0 기준): 약 18383MiB(ORPO) -> 9487MiB(ORPO in Unsloth)
- 최적화된 훈련환경을 제공하여 훈련 결과에 나온 loss값이 같은 ORPO 설정값 기준 약 9.1 -> 3.9로 감소
- Huggingface 업로드를 비롯하여 GGUF, vLLM형태의 모델로 저장 지원
- 2024년에 나온 오픈소스 라이브러리로 현재진행형 업데이트
○ 설치방법 (내가 사용하는 GPU가 빵빵하다! 라면 이 코드를 사용한다.)
!pip install "unsloth[cu121-ampere-torch230] @ git+https://github.com/unslothai/unsloth.git"
- 설치를 잘못하여서 재설치해야하는 경우
!pip uninstall unsloth -y이것을 실행하고 unsloth 공식 깃헙의 readme.md에서 자신에게 맞는 설치 방법을 사용한다.
○ 사용 방법: 공식 github 링크에 있는 colab 예제를 사용하는 방법이 제일 무난함
- Llama3 + ORPO + Unsloth의 경우의 데이터 형식: 문자열만 담은 instruction, input, accepted, rejected
-> instruction은 모델 text 생성에서의 prompt (system) 설정을 의미한다.
-> 기존 ORPO 데이터 형식에 요구된 각 컬럼의 복잡한 dict형태보다 상대적으로 간결함
- 데이터 형식의 유연성: 기존 데이터에 담긴 컬럼 이름이 다르고 instruction이 없어도 될까?
-> 본문 작성일 기준으로 이와같이 데이터 형식을 맞추지 않고 작동하는 법은 발견하지 못함
-> ORPO접목 시도 연구때와 마찬가지로 완벽하게 형식을 맞추는 것이 불필요한 오류 디버깅 없이
연구 진행 효율을 높여주는 지름길.
○ 훈련 방법: 공식 github에 게시된 ORPO 예제코드들을 Llama3 8b로 적용하여 그대로 사용
- 형식을 맞춘 데이터 파일의 샘플 100개를 뽑아 unsloth기반 환경에서 ORPO 훈련 시행
그런데 여기서 훈련 전후로 GPU, 메모리 사용량을 측정해서 알려주는 코드 + 훈련을 효율적으로 진행시켜주는 코드는 다음과 같다.
# 학습 전 GPU, 메모리 상태 점검
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
# 훈련 시작
try:
trainer_stats = trainer.train(resume_from_checkpoint=True)
except ValueError:
print("No valid checkpoint found. Training from scratch...")
trainer_stats = trainer.train()
except RuntimeError:
print("Size is mismatching. Training from scratch...")
trainer_stats = trainer.train()
# 훈련 후 GPU, 메모리 상태 결과
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
# wandb를 사용했다면 여기서 finish()를 써준다.
wandb.finish()GPU = NVIDIA RTX A6000. Max memory = 47.536 GB.
6.992 GB of memory reserved.
==((====))== Unsloth - 2x faster free finetuning | Num GPUs = 1 (unsloth은 현 작성일 기준 단일 GPU 훈련만 가능)
\\ /| Num examples = 6,297 | Num Epochs = 1
O^O/ \_/ \ Batch size per device = 2 | Gradient Accumulation steps = 4
\ / Total batch size = 8 | Total steps = 787
"-____-" Number of trainable parameters = 335,544,320
2199.1233 seconds used for training.
36.65 minutes used for training.
Peak reserved memory = 11.238 GB.
Peak reserved memory for training = 4.246 GB.
Peak reserved memory % of max memory = 23.641 %.
Peak reserved memory for training % of max memory = 8.932 %.
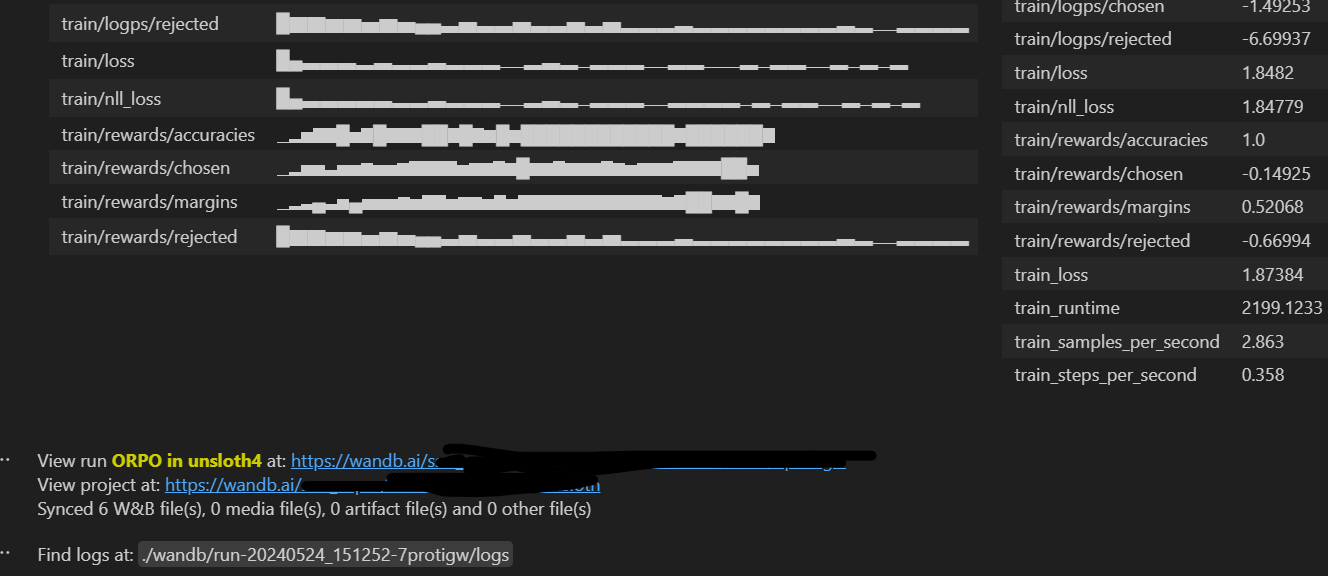
*** wandb: ML/AI 모델에 대한 학습진행 관련 지표 시각화 및 각종 편의 기능을 제공하는 라이브러리
wandb를 사용한 경우, 마지막에 이와같이 간단한 시각화와 요약 결과, 그래프를 볼 수 있는 링크를 제공한다.
nvidia-smiGPU나 메모리 사용량 측정은 터미널에 이것을 입력하는 것으로 해결이 될 수 있지만... 그냥 위에 저 코드로 측정해주는 것이 편하다. 최고점을 알아서 측정해주기 때문이다.
wandb라이브러리를 같이 쓰는 것도 방법이다.
우선 wandb에 가입을 하고 다음과 같이 알아서 설정한다.
import wandb
wb_token = '개인 토큰값 입력'
wandb.login(key=wb_token)# wandb에서 열람할 프로젝트 이름 및 장소 설정
wandb.init(project="내가 훈련한 것을 담는 파일 이름", name = "내가 훈련한 것의 이름", reinit=True)
훈련 때에 wandb를 설정할 수 있다.
from trl import ORPOConfig, ORPOTrainer
trainer = ORPOTrainer(
. . .
args = ORPOConfig(
. . .
report_to="wandb",
. . .
remove_unused_columns=False, # 필자는 이걸 False로 설정했다. 경고창 뜨는게 싫어서..
save_strategy = "steps", # 이걸 해줘야 resume training 옵션이 설정된다.
save_steps = 500, # 전체 step 개수를 확인하고 알아서 적절하게 설정하자.
)
. . .
)이런식으로 중간에 report_to 값을 설정해주면 wandb로 자동으로 리포트 시각화가 기록된다.
[파라미터 주의점]
max_steps = 30을 설정하면 데이터 양과 상관없이 30 step으로 훈련이 종료되므로 제대로 훈련이 안된다.
max_steps 설정 자체를 안하면 알아서 필요한 step만큼 설정해서 훈련한다. 과적합 등의 이유로 임의로 step을 제한할 때 사용한다.
unsloth을 사용하는 경우 공식 ORPO 논문에 적힌 learning_rate를 사용하면 필자는 loss값이 오히려 높게 나왔다. 그냥 default값(아예 주석처리)을 사용하는 것이 적절하다. 훈련 과정에서 최적화를 위해 필요할 때에 조절한다.
중간에 훈련에 관한 resume 코드는 훈련을 하는 가상의 서버가 끊어지거나 하는 불상사로 훈련 과정이 날아가는 것을 방지하는 옵션이다. 그러나 이것은 처음 훈련할 때에는 설정을 할 수가 없으므로 try, except를 통해 매 번 훈련할 때마다 코드를 수정해야하는 번거로움을 막는다.
wandb를 연결하여도 자동으로 wandb에서 기록된 훈련 덕분에 기존 훈련기록 및 시간이 낭비되지 않도록 바로 이어서 작업을 해준다. (그러나 wandb를 쓸 수 없는 환경이라면 위 resume옵션은 필수!)
○ 추론 방법: 같은 설정값을 기준으로 기존 추론 코드는 최소 1분 30초 이상 걸림
그러나 unsloth전용 추론 코드 사용시 10초 이내.
모델로드 + 프롬프트 설정
from unsloth import FastLanguageModel
from transformers import TextStreamer
import torch
max_seq_length = 4096 # Choose any! We auto support RoPE Scaling internally!
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "모델 경로", # 모델 적용
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
추론 코드
# 특이점: 영어로 된 답변이 모범답안과 가까운 경향성이 있음
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"You are an AI assistant designed to answer simple questions.", # instruction 영어로 작성시 영어로만 답변
"질문 ", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, temperature=0.2, do_sample=True, max_new_tokens = 128)
Setting `pad_token_id` to `eos_token_id`:144783 for open-end generation.
<|begin_of_text|>Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
You are an AI assistant designed to answer simple questions.
### Input:
질문~~~~~~~~~~~~~~~~~~~~
### Response:
The following field practices are necessary to determine the damage done by a small parse: ~~ 대충 답변
도입 과정에서의 문제점과 해결
○ 데이터 형식의 불일치 문제: 기존 ORPOtrainer에 맞춘 데이터는 Unsloth과 형식이 맞지않아 오류 발생
- rejected 컬럼은 기본으로 필요하지만 생성 시간이 걸리므로 기존 ORPO를 위해 형식을 맞춘 파일을 Unsloth에 맞게 재조정.
- 새로 생성한 instruction 컬럼의 내용은 "You are an AI assistant designed to answer simple questions.
Please restrict your answer to the exact question asked." 로 통일하여 문자열만 일괄 적용.
○ RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1!
-> 기존의 device_map=torch.device("cuda:0") 설정을 FastLanguageModel.from_pretrained()에 적용 못함
-> 다음의 코드를 jupyter notebook기준 제일 위에 셀에 사용하여 cuda:0을 설정하여 해결
# cuda 번호 설정
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
print("CUDA_VISIBLE_DEVICES is set to:", os.environ["CUDA_VISIBLE_DEVICES"])해당 코드는 unsloth 개발자가 직접 알려준 방법이다.
○ 독립된 형태로의 모델 저장코드?
model.save_pretrained_merged("저장할 경로", tokenizer, safe_serialization = None)Unsloth: Merging 4bit and LoRA weights to 16bit...
Unsloth: Will use up to 250.09 out of 377.51 RAM for saving.
100%|██████████| 32/32 [00:00<00:00, 36.23it/s]
Unsloth: Saving tokenizer... Done.
Unsloth: Saving model... This might take 5 minutes for Llama-7b...
Done.
이거 쓰면 됨
○ Unsloth은 AutoModelForCausalLM.from_pretrained()가 아닌 FastLanguageModel.from_pretrained()을 사용하므로 기존에 사용하던 문법과 다른 부분이 있음
-> 기존 문법에 작동하던 코드 진행과의 호환성 문제? -> 생각보다 별로 없음
○ 갑자기 잘 작동되던 라이브러리가 import에서 오류가 생긴다?
-> 해당 작업창, 혹은 프로그램(vscode 등)을 끄고 다시 들어가서 실행해보자
○ 분명히 설치를 했는데 자꾸 오류가 생긴다?
-> 최소한 Python 3.10.14 버전 이상을 사용하여야 한다. (torch 등의 라이브러리 버전도 최신이 좋음)
결론
○ ORPO tuned model in Unsloth은 성능이나 효율면에서 우수하므로 사용하면 좋음
'TechStudy > LLM' 카테고리의 다른 글
| 고급(?) 파인튜닝 기술 Reranker (0) | 2024.06.12 |
|---|---|
| LoRA? 신 기술 MoRA를 사용해보자! (0) | 2024.06.11 |
| Fine-tuned model 독립 및 견고성(robust) 검증 (0) | 2024.06.05 |
| Llama3, 그리고 ORPO (0) | 2024.06.04 |
| Llama3 and ORPO (리딩용) (0) | 2024.05.13 |


