KN 분류: 말 그대로 주변 바탕으로 (분류 번호 예측 후) 자동 분류 작업
KN 회귀: 주변 바탕으로 특정 데이터 값을 예측
이번 데이터는 농어의 길이와 무게 샘플을 바탕으로 잘못 측정된 한 농어의 무게를 추정하는 상황이다.(길이는 괜찮다.)
import numpy as np
perch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
perch_length, perch_weight, random_state=42)
# 종류가 하나 뿐이므로 stratify를 굳이 사용하지 않는다. 생략시 stratify = False 적용
# 해당 split 함수는 length(input)를 통해 weight(target)를 예측하는 구조이다.
print(train_input.shape, test_input.shape)(42,) (14,)
문제점은 해당 배열이 1차원. 사이킷런은 2차원 mtx(배열) 다루는 것을 예상하기에 인위적으로 바꿔줘야함.
이는 reshape(-1, 1)로 可 (-1로 나머지 원소 개수로 자동정렬)
예제)
test_array = np.array([1,2,3,4])
print(test_array.shape)(4,) <- 1차원 배열을 바꿔보자
test_array = test_array.reshape(-1, 1)
test_array # -1이 아닌 경우 해당 size mtx 출력(단 원소 개수 일치해야함)array([[1],
[2],
[3],
[4]])
1차원을 2차원으로 바꾼 모습이다. 해당 행렬의 크기는 test_array.shape에 의해 (4.1)로 출력된다.
즉, 적용하면
train_input = train_input.reshape(-1, 1) # 1행 기준으로 세로로 변환(ML학습위해)
test_input = test_input.reshape(-1, 1)
print(train_input.shape, test_input.shape)(42, 1) (14, 1)
이제 머신러닝 회귀를 적용하자
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor() # k-최근접 이웃 회귀 모델 훈련
knr.fit(train_input, train_target)
knr.score(test_input, test_target)0.992809406101064 <- Coefficient of determinination(결정계수)이다. KN classify에서는 맞춘 개수의 비율이였다.

높으면 정확도 높고 낮으면 정확도 낮다.
target ~ 예측값 -> 분자가 0이됨 -> 1에 가까워짐 -> 높은 정확도.
평균값 ~ 예측값 -> 분자가 분모와 거의 같아짐 -> 0에 가까워짐 -> 낮은 정확도
결정계수 정확도는 MAE로 확인한다.
from sklearn.metrics import mean_absolute_error # 단독으로 잘 사용은 안함. MAE
# test set 예측
test_prediction = knr.predict(test_input) # the coefficient of determination
mae = mean_absolute_error(test_target, test_prediction) # test set 평균 절댓값 오차 계산(MAE)
print(mae)19.157142857142862 <- target과 예측값의 차이 평균이다. (평균 19g 차이)
그렇다면 train data의 결정계수는 어떠할까?
print(knr.score(train_input, train_target))0.9698823289099254
결정계수 값이 train data < test data 인 이상한 결과 도출
[다시 개념정리]
Overfitting(과대적합): 정확도가 train은 좋은데 test가 엉망인 경우; 실전 예측성 떨어짐
Underfitting(과소적합): 정확도가 train은 엉망인데 test가 좋은 경우; 또는 두 점수 모두 너무 낮은 경우
why?) model is too simple!! or data set is too small! -> not trained well
여기선 underfitting 문제 발생!
본 예제에서는 데이터 크기를 더 늘릴 수 없으니 model 복잡화를 진행한다.
KN 회귀에서는 n 개수를 줄임으로써 복잡화를 진행(데이터 경향따르기보다 적은 데이터로 회귀해야하니 복잡해짐)
n_neighbors
knr.n_neighbors = 3 # 근방 개수 줄임(복잡화)
knr.fit(train_input, train_target) # model 재훈련
print(knr.score(train_input, train_target))
print(knr.score(test_input, test_target))0.9804899950518966 <- train
0.9746459963987609 <- test
underfitting 문제 해결
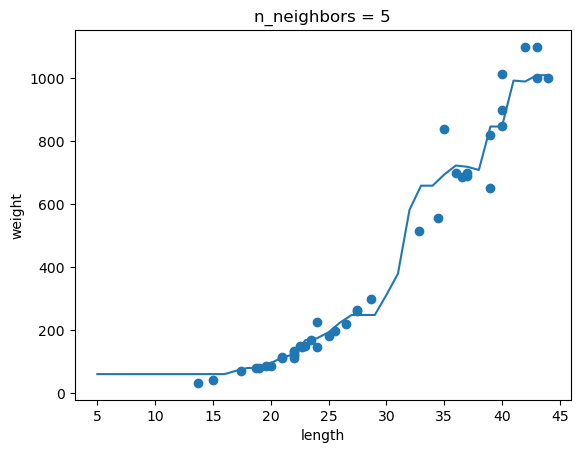
실제로 n의 값이 커질수록 예측선은 단순해진다.
# k-최근접 이웃 회귀 객체를 만듭니다
knr = KNeighborsRegressor()
# 5에서 45까지 x 좌표를 만듭니다
x = np.arange(5, 45).reshape(-1, 1)
# n = 1, 5, 10일 때 예측 결과를 그래프로 그립니다.
for n in [1, 5, 10]:
# 모델 훈련
knr.n_neighbors = n
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
# 지정한 범위 x에 대한 예측 구하기
prediction = knr.predict(x)
# 훈련 세트와 예측 결과 그래프 그리기
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.title('n_neighbors = {}'.format(n))
plt.xlabel('length')
plt.ylabel('weight')
plt.show()

이 머신러닝을 실제 50cm의 경우를 예측하는데에 적용해보자
print(knr.predict([[50]]))[1033.33333333]
42cm or 43cm의 무게가 1033근처인데 50cm도 차이가 없다는 점이 이상하다.
그래프를 확인하면
import matplotlib.pyplot as plt
distances, indexes = knr.kneighbors([[50]]) # 50cm 농어 이웃 3개
print('indexes : ', indexes)
print('distances : ', distances)
plt.scatter(train_input, train_target) # 훈련 세트 산점도
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
# 훈련 세트 중 이웃 샘플 Diamond
plt.scatter(50, 1033, marker='^') # 50cm 농어 데이터
plt.show()indexes : [[34 8 14]]
distances : [[6. 7. 7.]]

print(knr.predict([[100]])) #길이가 100이면 무게가 얼마나 될까? (결과가 이상함)[1033.33333333]

KN 근접방식을 바탕으로한 회귀 알고리즘의 한계인듯 하다.
선형회귀 알고리즘을 사용해야한다.
lr.coef_ lr.intercept_
from sklearn.linear_model import LinearRegression
lr = LinearRegression() # 선형회귀 객체화
lr.fit(train_input, train_target) # 훈련
print(lr.predict([[50]])) # 50cm 농어에 대한 예측 출력
print(lr.coef_, lr.intercept_) #회귀선 계수(기울기)와 절편값 출력
plt.scatter(train_input, train_target)
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_+lr.intercept_])
# 15에서 50까지 1차 함수 그래프 생성위해 범위 지정. 즉, interval: x in [15,50] & y는 회귀식 in []
plt.scatter(50, 1241.8, marker='^') # 50cm 농어 데이터
plt.show()[1241.83860323] <- 50cm 농어 예측 weight
[39.01714496] -709.0186449535477 <- 회귀선 계수 및 절편값

print(lr.score(train_input, train_target)) # train 회귀 정확도 측정.
print(lr.score(test_input, test_target)) # test 회귀 정확도 측정0.9398463339976039
0.8247503123313558
근데 이 선은 무게가 0 밑으로 내려가는 경우를 상정한다는 문제점이 있다.
-> 직선보단 곡선으로 정확도를 높여보자.
2차함수 생성위해 그냥 x제곱한 항목 추가하고, 같이 stack로 묶어 새로 정의한다.
train_poly = np.column_stack((train_input ** 2, train_input)) # 제곱이랑 그냥 x데이터 삽입
test_poly = np.column_stack((test_input ** 2, test_input))
print(train_poly.shape, test_poly.shape) #multi linear regresssion(42, 2) (14, 2)
lr = LinearRegression() # 객체화
lr.fit(train_poly, train_target) # 훈련
print(lr.predict([[50**2, 50]])) # 제곱한 항에 맞춰서 input도 제곱값 , 기존값 같이 적용
print(lr.coef_, lr.intercept_)[1573.98423528]
[ 1.01433211 -21.55792498] 116.0502107827827
point = np.arange(15, 50) # 구간별 직선 그리기 위해 15에서 49까지 정수 배열 생성
plt.scatter(train_input, train_target)
plt.plot(point, 1.01*point**2 - 21.6*point + 116.05) # 15에서 49까지 2차 함수 그래프
plt.scatter([50], [1574], marker='^') # 50cm 농어 데이터 1574는 위 predict 값에서 가져옴
plt.show()
print(lr.score(train_poly, train_target)) # 정확도 수치 파악
print(lr.score(test_poly, test_target))
0.9706807451768623 <- train set
0.9775935108325122 <- test set 정확도가 이전보다 상승 (그러나 train<test 라서 찜찜한 부분이 아직도 남음)
다음 게시물에서 계속
'Programming > Python' 카테고리의 다른 글
| [Numpy] Linear algebra package (0) | 2023.09.13 |
|---|---|
| [ML] Feature engineering, 다중회귀, 릿지회귀, 라쏘회귀 (1) | 2023.09.11 |
| [ML] KN 분류 알고리즘 (실전편) (0) | 2023.09.11 |
| [ML] KN 분류 알고리즘 (기본편) (0) | 2023.09.11 |
| [ML] Gradient Descent(경사하강법) (1) | 2023.09.07 |



